Make教程:用Make + OpenAI打造零人工干预的每日新闻播客
通过Make串联Notion、OpenAI和Google Drive,将碎片化阅读列表自动转化为高质量音频播客,实现全自动内容生产。
准备好开始自动化了吗?
使用 Make.com 构建此工作流 — 入门版永久免费。
概述
对于内容创作者和信息焦虑者来说,这是一个高价值的生产力构建方案。通过Make串联Notion、OpenAI (GPT-4o) 和Google Drive,可以将碎片化的阅读列表自动转化为高质量的音频播客。
本教程将教你搭建一个完全自动化的播客生产系统:
- 自动抓取 Notion中的新闻/文章列表
- AI生成 播客脚本文案
- 语音合成 生成MP3音频文件
- 自动存储 上传到Google Drive
完成后,系统每天自动生成播客,完全无需人工干预!
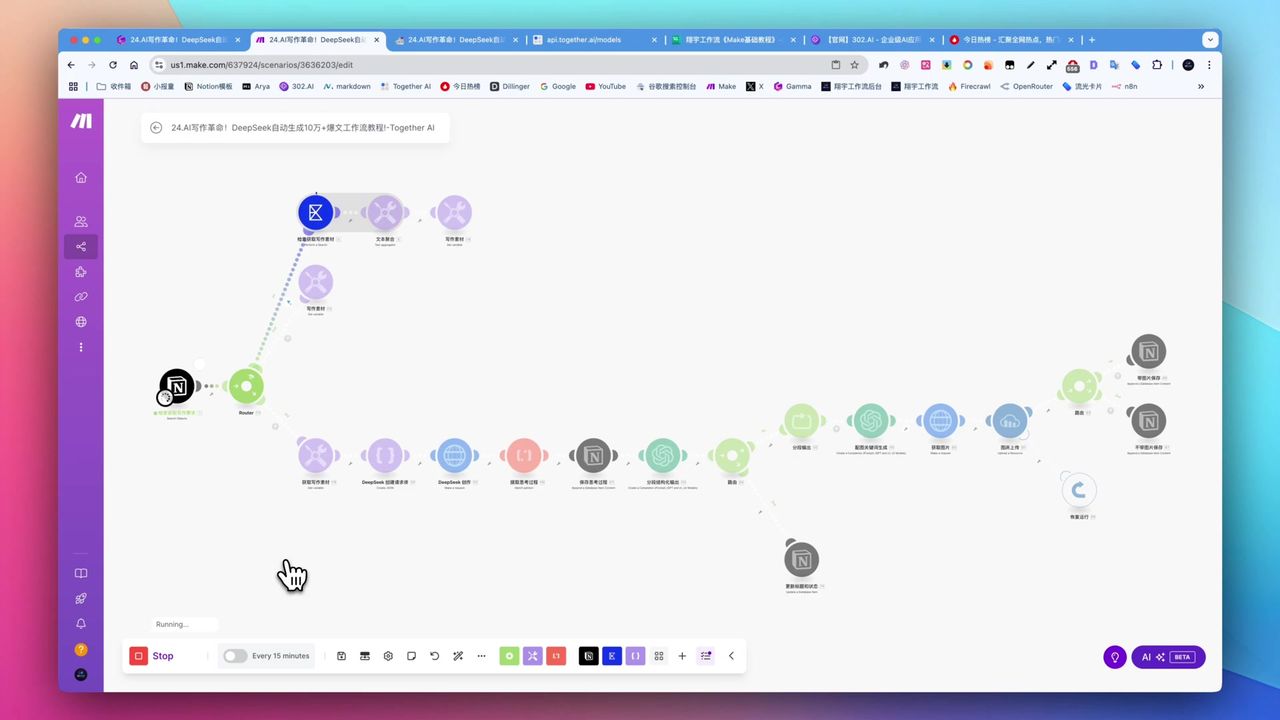
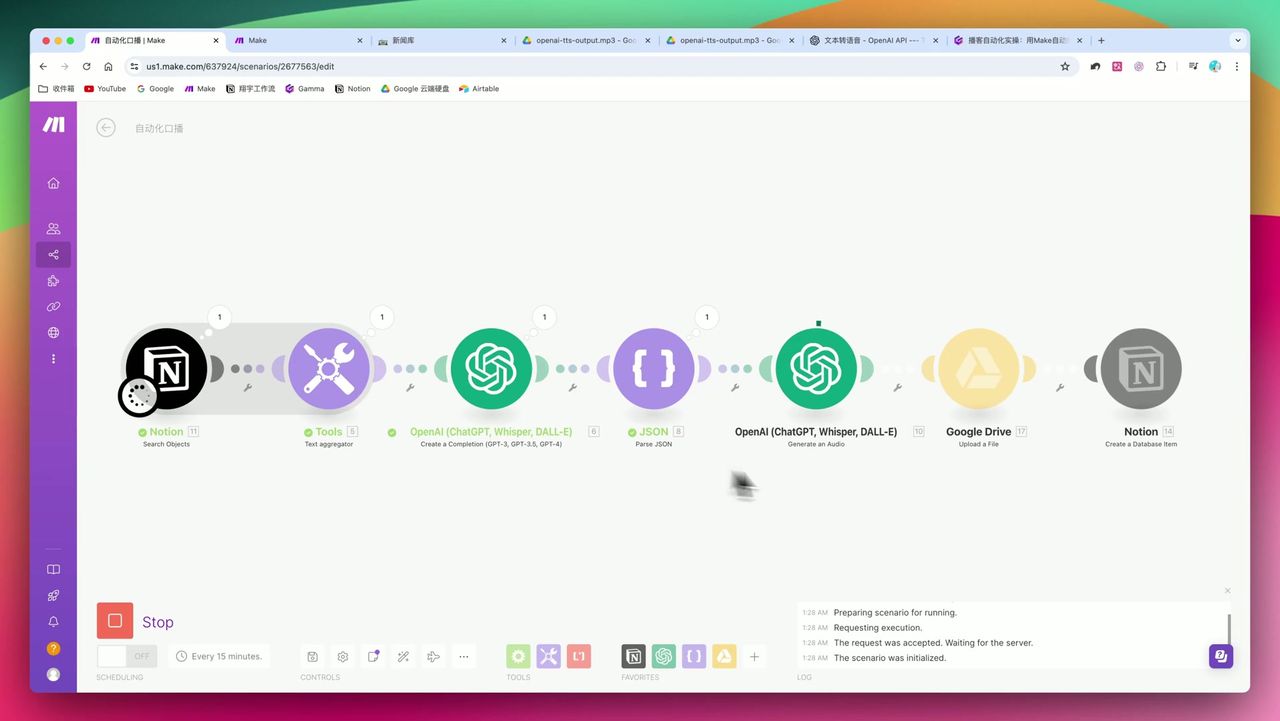 从Notion到OpenAI再到Google Drive的完整自动化流程
从Notion到OpenAI再到Google Drive的完整自动化流程
核心决策因素
在选择此类自动化方案时,你需要关注:
- 集成深度 - 是否支持你现有的知识库(如Notion)和云存储(如Google Drive)
- AI模型质量 - 生成的文案是否自然?TTS(语音合成)是否僵硬?
- 数据结构处理 - 能否处理数组聚合(Aggregator)和结构化数据(JSON)
- 扩展性 - 未来是否支持多语言翻译或分发到不同平台
技术规格参考
| 参数项 | 设定值 | 备注 |
|---|---|---|
| 核心模型 (LLM) | GPT-4o | 质量更高,适合生成核心文案,但成本较高 |
| 最大Token数 | 2,000 | 针对1000-2000字的播客脚本预留空间 |
| 音频生成模型 | OpenAI TTS | 支持多语言,自动根据文本语言生成对应语音 |
| 音频语速 | 1.1x 或 1.2x | 提高信息获取效率,符合现代听众习惯 |
| 音频格式 | MP3 | 通用性最强,便于存储和分发 |
| 单次处理条目数 | 3条 | 用于演示聚合功能 |
| 输出格式要求 | JSON | 强制AI输出JSON格式以便后续拆分标题和正文 |
前置准备
在开始之前,请确保你已经准备好:
- Make.com 账号(免费注册)
- Notion 账号和一个新闻/文章数据库
- OpenAI API 密钥(用于GPT-4o和TTS)
- Google Drive 账号(用于存储音频文件)
Step 1: 配置Notion数据源
首先在Notion中创建或准备一个文章数据库,包含以下字段:
- 标题 (Title)
- 内容摘要 (Text)
- 日期 (Date)
- 状态 (Select) - 如”待处理”、“已生成”
在Make中添加Notion Search模块,配置:
- 选择你的数据库
- 设置筛选条件(如日期为今天)
- 限制返回条目数(如3条)
Step 2: 使用Text Aggregator聚合数据
这是流程中至关重要的一步,很多新手会在这里卡住。
 将多条Notion数据聚合成一个文本块
将多条Notion数据聚合成一个文本块
为什么需要聚合?
如果不使用Aggregator,每条Notion数据会单独触发一次OpenAI调用,导致:
- API被多次零散调用,浪费成本
- 生成的播客是碎片化的,缺乏连贯性
配置步骤:
- 添加Text Aggregator模块
- 设置源模块为Notion Search
- 定义聚合格式,如:
标题:{{title}}\n摘要:{{summary}}\n\n
Step 3: 配置OpenAI生成播客脚本
这是核心技术点:通过Prompt Engineering控制AI的输出格式。
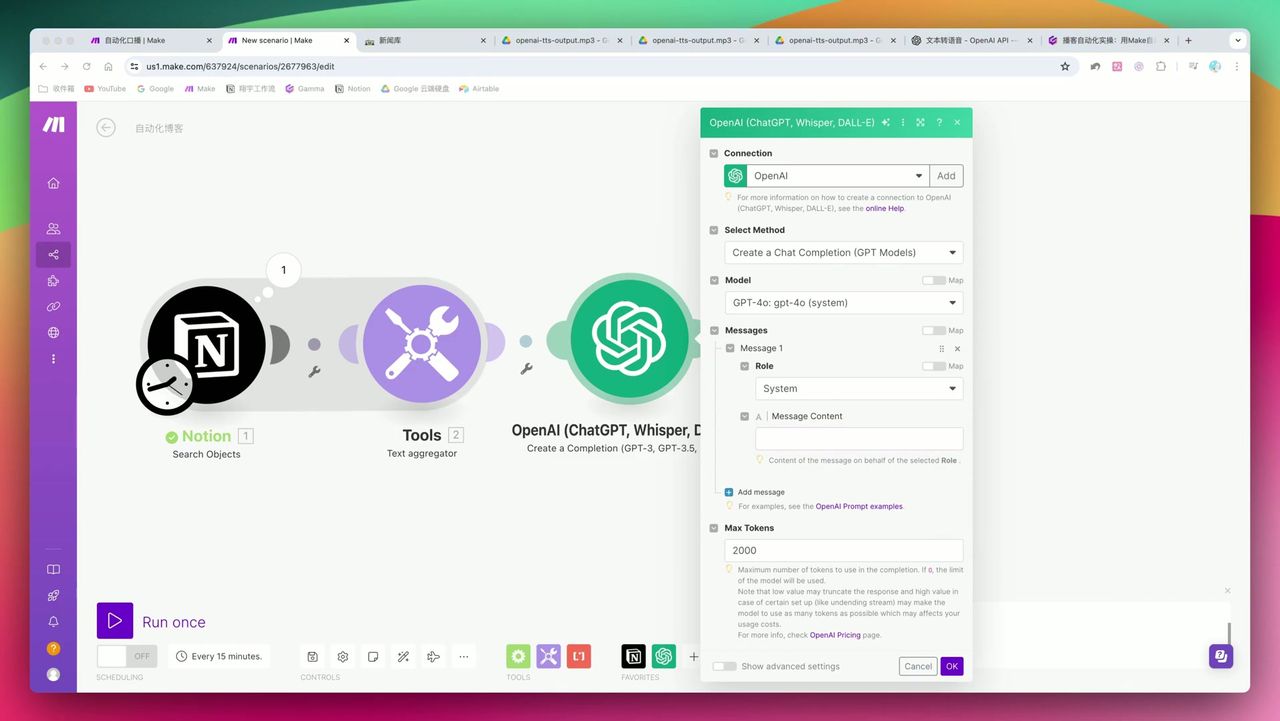 System角色定义和JSON格式的强制要求
System角色定义和JSON格式的强制要求
Prompt设计要点
System角色:
你是一位专业的播客主持人,擅长将新闻资讯转化为生动有趣的口播稿。
请严格按照JSON格式输出,包含title和content两个字段。User消息:
请将以下新闻摘要转化为一期5分钟的播客脚本:
{{聚合后的文本}}
输出格式示例:
{"title": "今日AI快讯", "content": "大家好,欢迎收听..."}关键参数设置
- Model: gpt-4o(质量更高)
- Max Tokens: 2000
- Response Format: 强制JSON
Step 4: JSON解析与数据提取
OpenAI返回JSON后,需要解析提取标题和正文。
添加JSON Parse模块:
- 输入:OpenAI的输出内容
- 输出:分离的title和content字段
注意:如果AI生成的JSON包含额外标点(如前缀逗号),会导致解析报错。建议在Prompt中明确要求”只输出纯JSON,不要任何前缀或后缀”。
Step 5: 生成语音文件
使用OpenAI的TTS(Text-to-Speech)将文案转为语音。
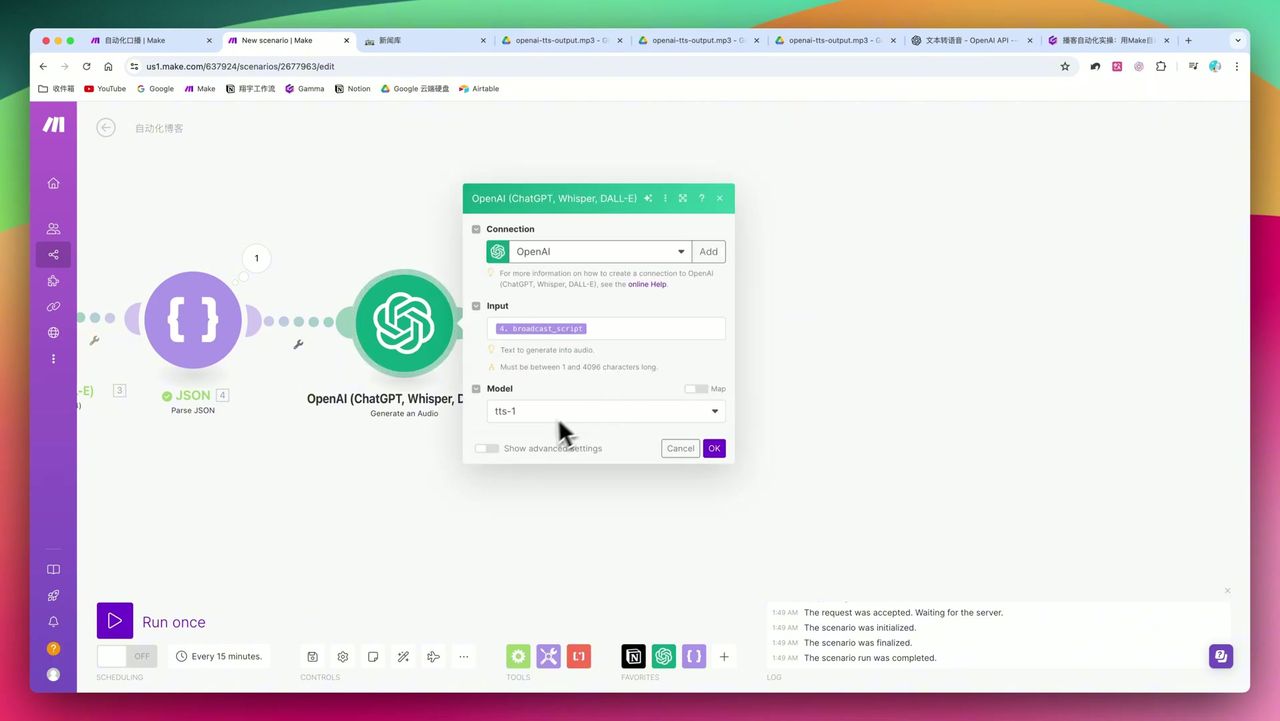 音色选择、速度设置和格式配置
音色选择、速度设置和格式配置
关键配置:
- Model: tts-1 或 tts-1-hd
- Voice: 选择合适的音色(如alloy、echo、nova等)
- Speed: 1.1x 或 1.2x(提高信息获取效率)
- Format: MP3
Step 6: 上传到Google Drive
最后,将生成的MP3文件上传到Google Drive。
- 添加Google Drive - Upload a File模块
- 选择目标文件夹
- 文件名使用动态变量:
{{title}}_{{formatDate(now; "YYYY-MM-DD")}}.mp3
最终效果
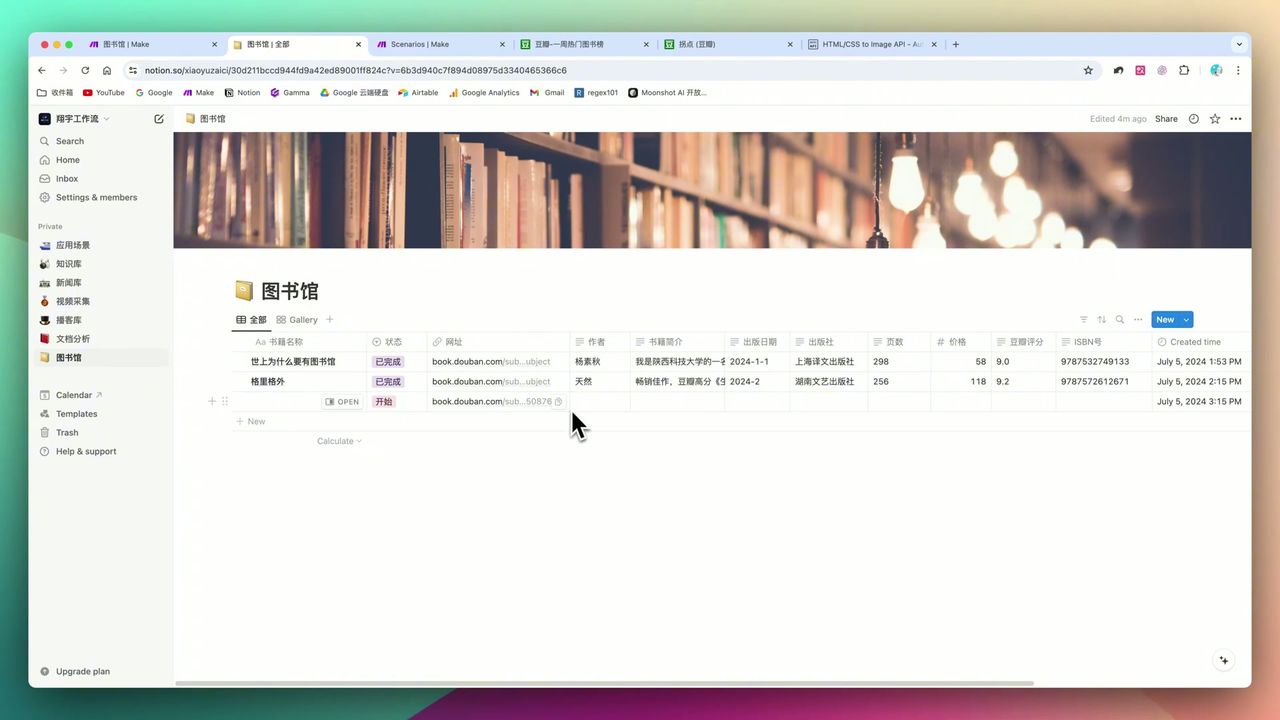
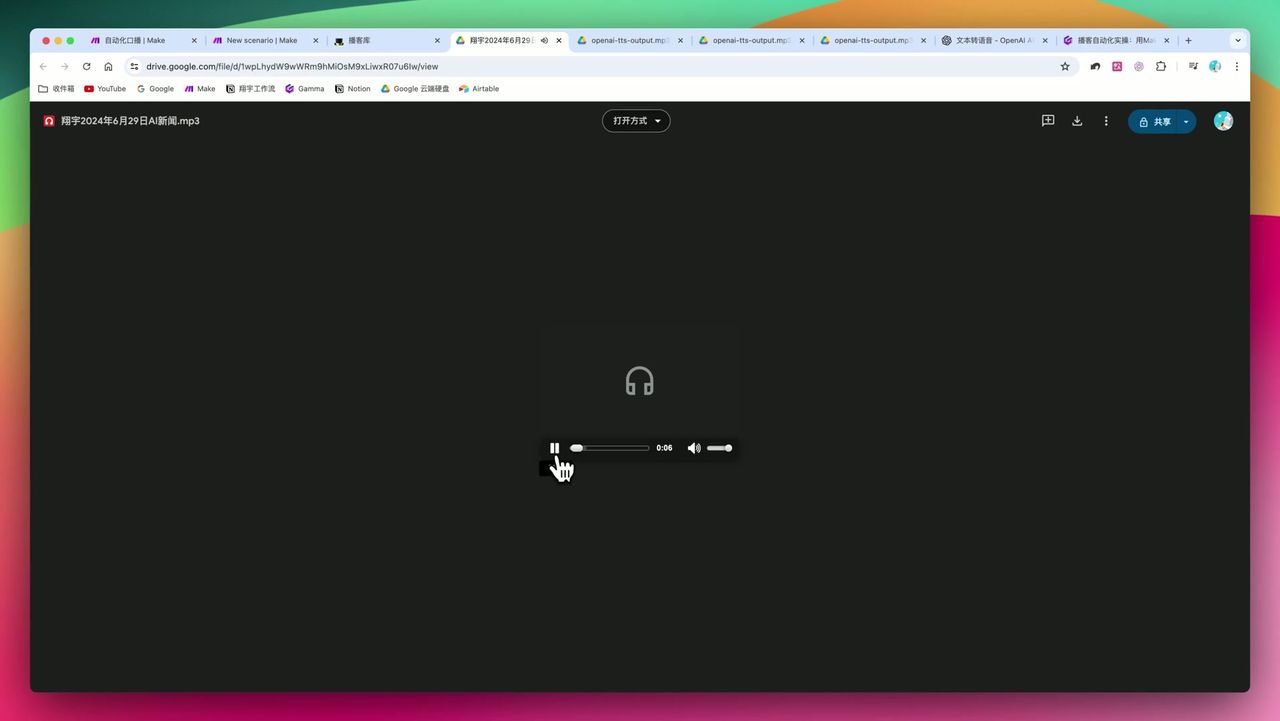 生成的播客标题、文案以及嵌入的音频文件
生成的播客标题、文案以及嵌入的音频文件
设置好时间触发器(如每天早上8点),系统会自动:
- 抓取昨天或当天的新闻
- 生成播客脚本
- 转换为语音
- 上传到云端
完全无需人工干预!
注意事项
在搭建过程中需要注意:
-
Make的交互逻辑 - 如果前置模块没有实际运行,后置模块无法获取变量。建议先试运行一次流程来”生成”数据样本。
-
JSON格式的脆弱性 - AI生成的内容可能包含额外标点,导致JSON Parse报错。在Prompt中明确要求纯JSON输出。
-
API成本控制 - GPT-4o + TTS每日运行成本需关注。如果成本敏感,可考虑使用GPT-3.5-turbo生成脚本。
-
数据聚合必要性 - 务必使用Text Aggregator,避免API被多次零散调用。
适用场景
推荐使用的用户
- 技术型内容创作者 - 希望将博客、Newsletter自动转为音频内容
- 信息极客 - 需要每天高效摄入特定领域资讯,习惯听音频
- 企业用户 - 需要自动生成每日早报或内部简报
可能不适合的情况
- 对JSON、Webhook、API Key完全没概念的零基础用户
- 对音质有广播级要求,需要专业主播演绎的场景
Make vs Zapier
虽然Zapier上手简单且生态更丰富,但在处理复杂逻辑时,Make具有明显优势:
| 对比项 | Make | Zapier |
|---|---|---|
| 数据聚合 | 原生支持Aggregator | 需要额外步骤 |
| 路由分支 | 可视化Router | 相对复杂 |
| 画布操作 | 直观的连线布局 | 线性步骤 |
| 复杂自动化 | 更适合 | 简单任务更适合 |
常见问题
这个工作流每天运行的API成本大概多少?
使用GPT-4o和TTS模型,每天生成一期1000-2000字的播客,API成本约在0.1-0.3美元,具体取决于内容长度和音频时长。
Make和Zapier哪个更适合这种自动化?
对于复杂的多步骤自动化(如数据聚合、JSON解析、多分支路由),Make的画布式操作更具优势。Zapier更适合简单的单步自动化。
生成的语音质量如何?
OpenAI TTS语音自然流畅,支持多语言,但缺乏专业主播的情感起伏和呼吸感,适合信息类播客而非故事类内容。
可以生成其他语言的播客吗?
可以。OpenAI TTS自动根据文本语言生成对应语音,输入英文内容可直接生成英文播客,甚至支持法语、德语等多语言。
下一步
学会了基础工作流后,你可以尝试:
- 添加多语言翻译模块,生成双语播客
- 集成到微信、小红书等平台自动分发
- 添加背景音乐和片头片尾
- 设置错误处理和重试机制
有问题欢迎在评论区留言交流!
常见问题
- 这个工作流每天运行的API成本大概多少?
- 使用GPT-4o和TTS模型,每天生成一期1000-2000字的播客,API成本约在0.1-0.3美元,具体取决于内容长度和音频时长。
- Make和Zapier哪个更适合这种自动化?
- 对于复杂的多步骤自动化(如数据聚合、JSON解析、多分支路由),Make的画布式操作更具优势。Zapier更适合简单的单步自动化。
- 生成的语音质量如何?
- OpenAI TTS语音自然流畅,支持多语言,但缺乏专业主播的情感起伏和呼吸感,适合信息类播客而非故事类内容。
- 可以生成其他语言的播客吗?
- 可以。OpenAI TTS自动根据文本语言生成对应语音,输入英文内容可直接生成英文播客,甚至支持法语、德语等多语言。