Make教程:用GPT-4o多模态能力自动构建Notion电子图书馆
结合HCTI网页截图和GPT-4o图像识别,自动从豆瓣读书页面提取书名、作者、评分等元数据,一键保存到Notion知识库。
准备好开始自动化了吗?
使用 Make.com 构建此工作流 — 入门版永久免费。
概述
这是一套利用GPT-4o多模态能力构建的智能图书管理方案。
通过网页截图+AI图像识别的创新方式,绕过传统爬虫限制,实现图书信息的自动采集:
- 触发任务 - Notion数据库状态变更触发
- 网页截图 - HCTI将豆瓣页面转为图片
- AI识别 - GPT-4o从图片中提取结构化数据
- 格式转换 - 确保输出为标准JSON格式
- 数据存储 - 自动回写Notion知识库
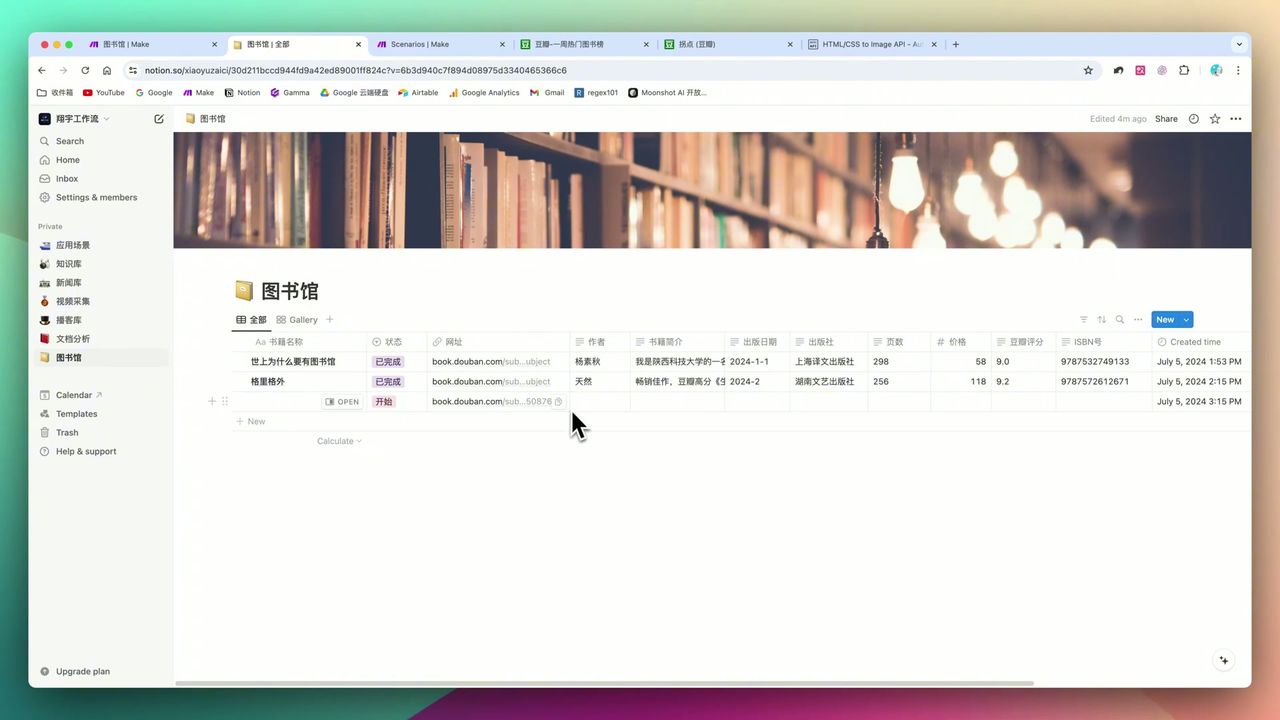 自动填充的图书信息展示
自动填充的图书信息展示
核心决策因素
在选择图书管理自动化方案时,需考量:
- 自动化效率 - 能否显著减少手动录入时间
- 数据准确性 - 提取的书名、作者、评分是否准确
- 易用性 - 搭建和维护的技术门槛
- 成本 - 第三方服务的免费额度和长期费用
- 扩展性 - 能否应用于其他数据采集场景
技术规格参考
| 规格项 | 参数值 | 备注 |
|---|---|---|
| HCTI免费额度 | 50次/月 | 网页截图服务 |
| 截图像素密度 | 建议设为3 | 提高清晰度确保识别准确 |
| GPT-4o Token | 1000-3000 | 根据需求调整 |
| 提取字段数 | 4-6个 | 书名、作者、出版社、页数、价格、评分等 |
前置准备
在开始之前,请确保准备好:
- Make.com 账号(免费注册)
- OpenAI API密钥(需支持GPT-4o)
- HCTI账号(htmlcsstoimage.com)
- Notion 账号和数据库
Notion数据库结构
创建图书管理数据库,包含以下字段:
- 书名 (Title) - 图书标题
- 链接 (URL) - 豆瓣图书页面链接
- 状态 (Select) - 待处理/开始/已完成
- 作者 (Text) - 作者信息
- 出版社 (Text) - 出版社名称
- 出版年 (Text) - 出版年份
- 页数 (Number) - 页数
- 价格 (Text) - 定价
- 豆瓣评分 (Number) - 评分
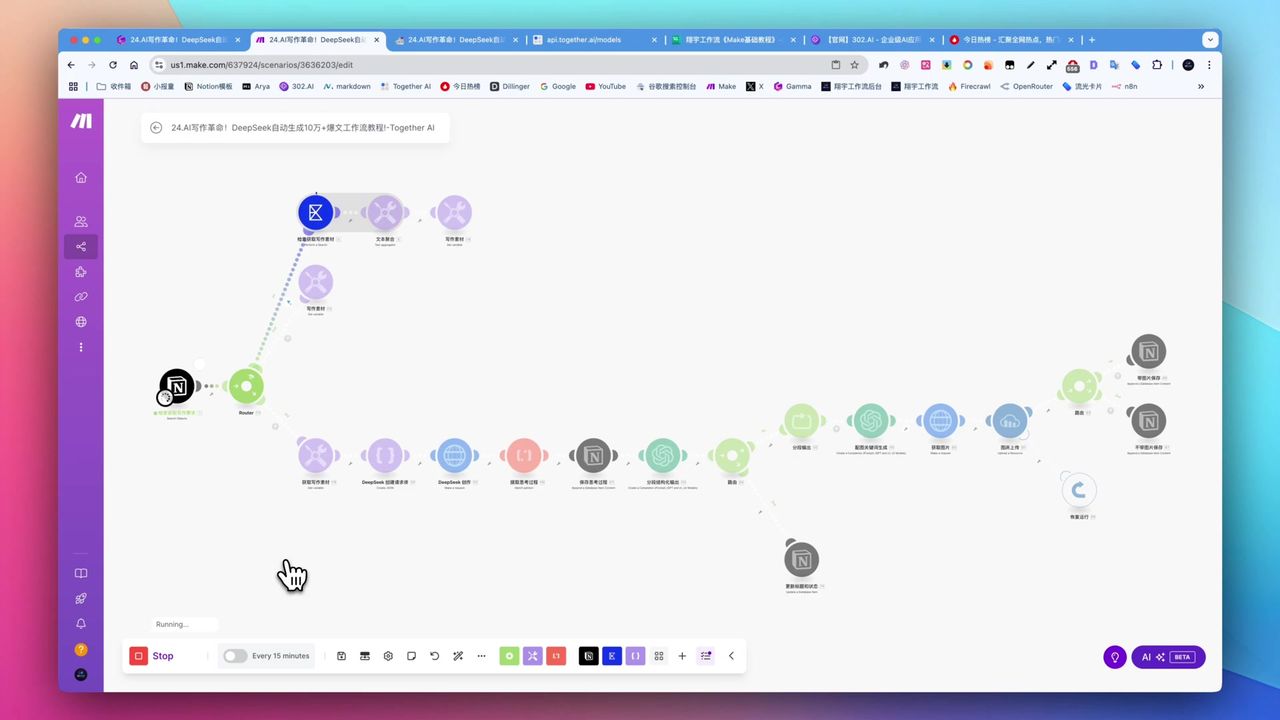
工作流架构
阶段一:触发与检索
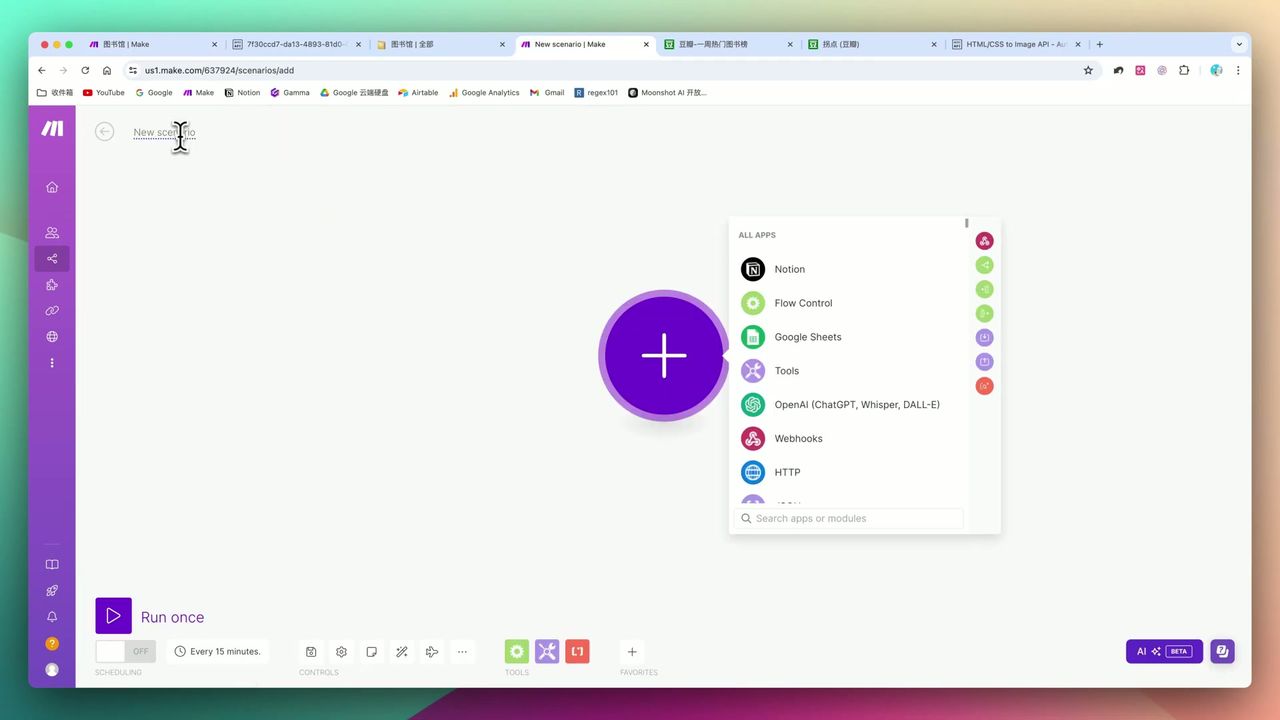 Notion数据库检索模块配置
Notion数据库检索模块配置
使用Notion Watch Database Items监控状态变更:
配置要点:
- 监控条件:状态字段变为”开始”
- 获取字段:链接URL
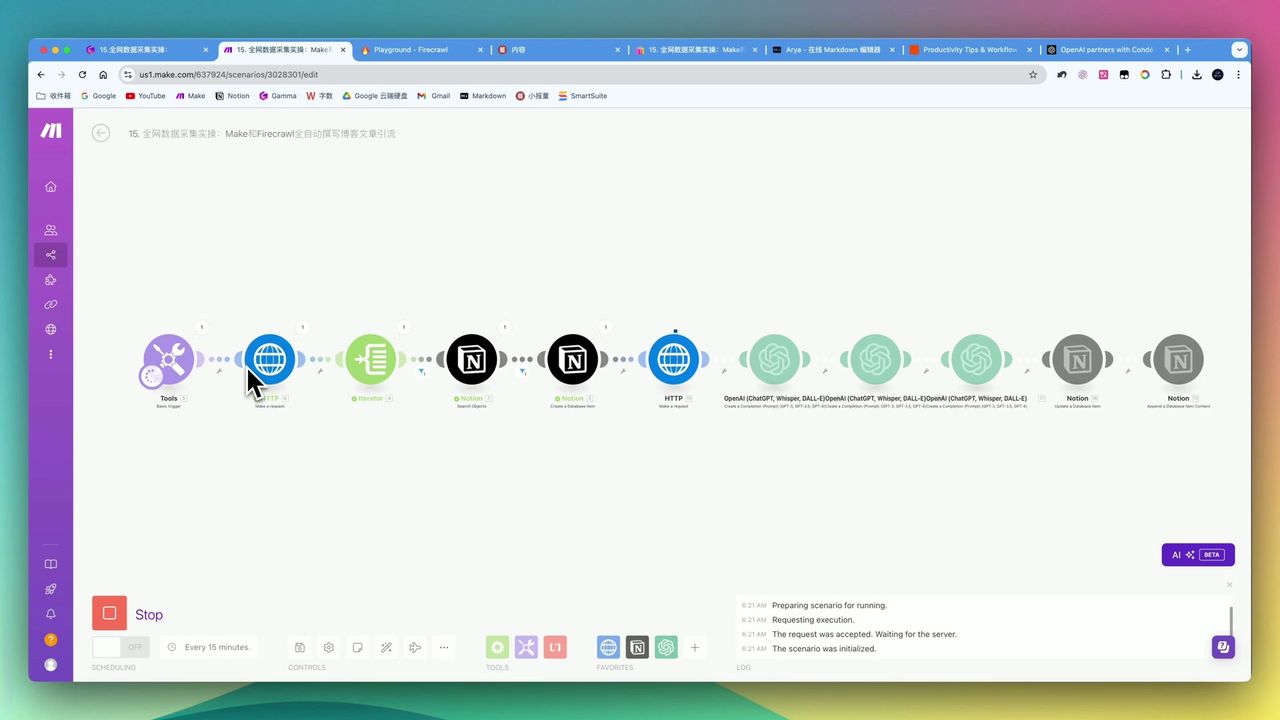
阶段二:网页截图
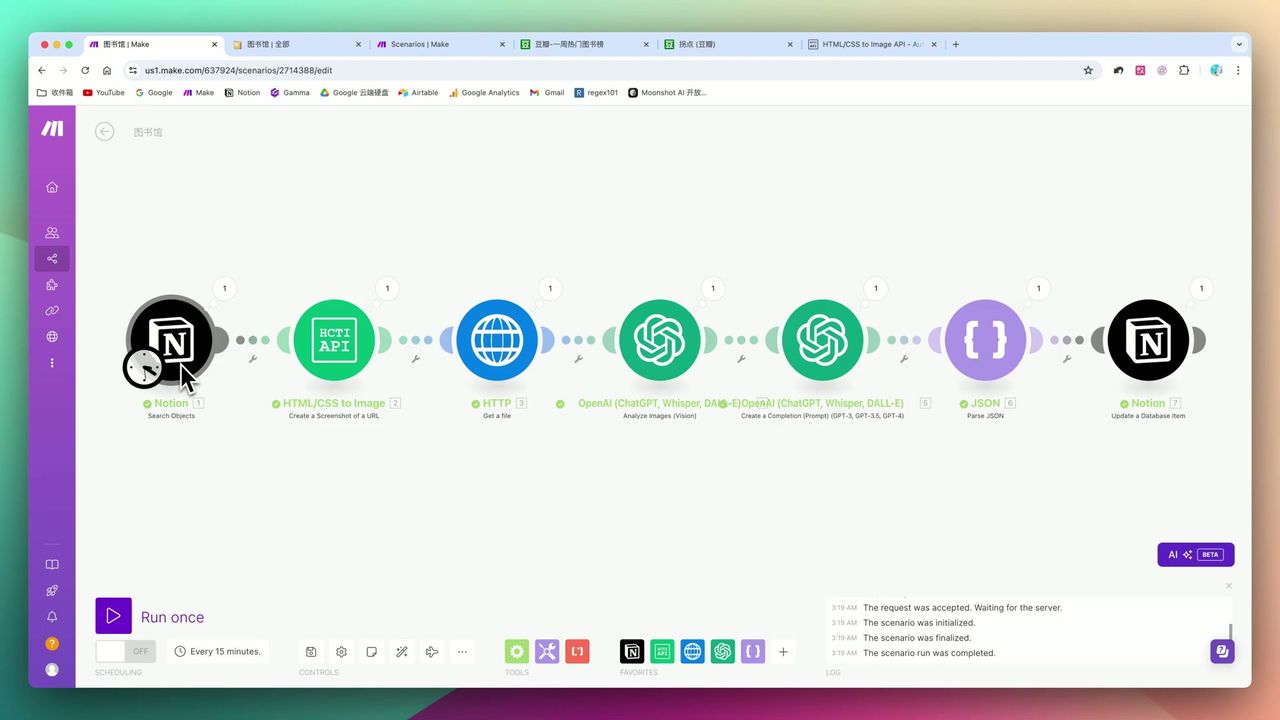 将URL转换为图片的HCTI模块
将URL转换为图片的HCTI模块
使用HCTI将豆瓣页面转换为图片:
配置要点:
- URL:从Notion获取的豆瓣链接
- 像素密度:设为3(提高清晰度)
- 输出格式:PNG或JPG
为什么用截图? 豆瓣等网站有反爬机制,直接抓取HTML困难。通过截图+AI识别的方式,可以绕过技术限制。
阶段三:GPT-4o多模态识别
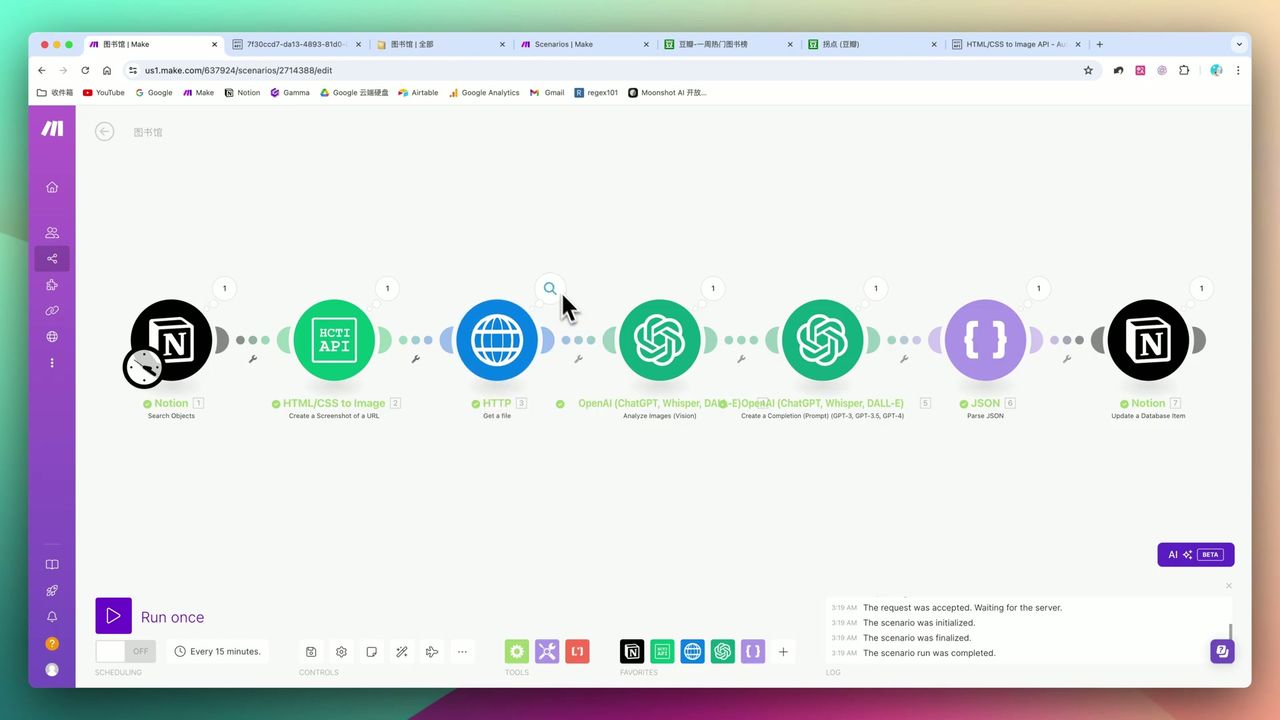 GPT-4o多模态模型识别图片内容
GPT-4o多模态模型识别图片内容
将截图发送给GPT-4o进行信息提取:
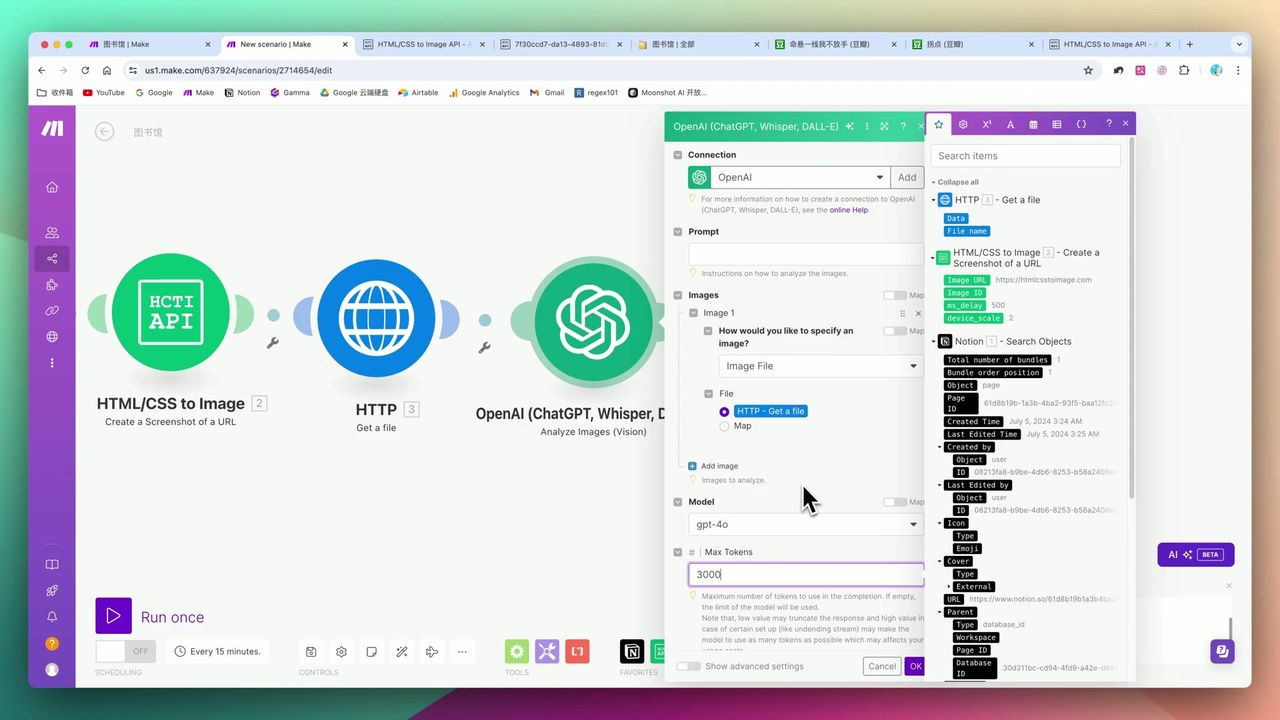 结构化提示词示例
结构化提示词示例
提示词设计:
请从这张豆瓣图书页面截图中提取以下信息:
1. 书名
2. 作者
3. 出版社
4. 出版年份
5. 页数
6. 定价
7. 豆瓣评分
请以JSON格式返回,字段名使用英文:
{
"title": "",
"author": "",
"publisher": "",
"year": "",
"pages": "",
"price": "",
"rating": ""
}阶段四:JSON格式保证
GPT-4o多模态模块无法100%保证JSON格式输出,需要额外处理:
解决方案:
- 添加一个普通的OpenAI对话模块
- 要求将上一步输出转换为标准JSON
- 确保数据可被后续模块正确解析
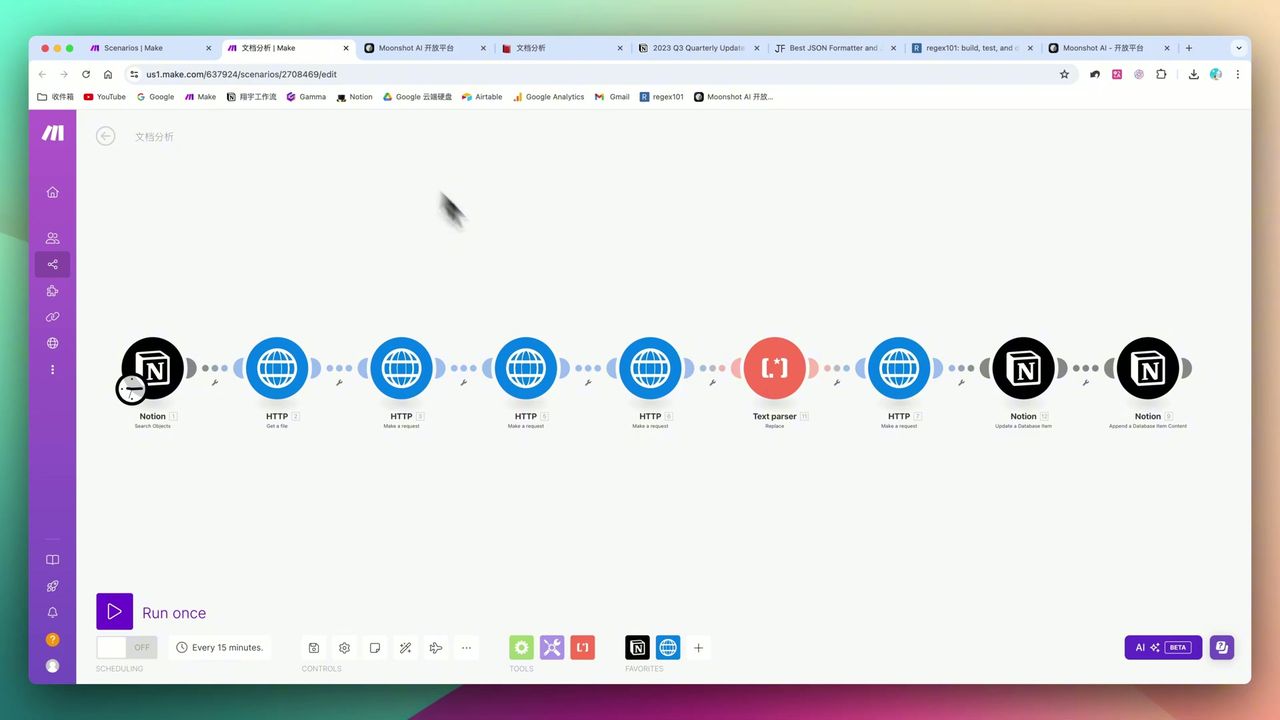
阶段五:回写Notion
将提取的结构化数据更新到Notion数据库:
映射关系:
- title → 书名
- author → 作者
- publisher → 出版社
- year → 出版年
- pages → 页数
- price → 价格
- rating → 豆瓣评分
- 状态 → 已完成
扩展应用
这套工作流不仅限于图书管理,还可以扩展到:
- 商品价格监控 - 截图电商页面,提取价格变化
- 股票走势分析 - 截图行情页面,提取关键数据
- 招聘信息抓取 - 截图招聘页面,提取岗位信息
- 竞品分析 - 截图竞品页面,提取产品信息
只需调整提示词,即可适应不同场景。
注意事项
在实操中容易遇到的”坑”:
-
识别准确性 - 基于图片识别可能有细微错误,复杂字母或特殊排版风险更高
-
JSON输出不稳定 - 多模态模块需要额外添加对话模块确保JSON格式
-
截图清晰度 - 像素密度建议设为3,太低会影响识别准确率
-
平台分享限制 - YouTube等平台可能限制包含JSON括号的内容分享
适用场景
推荐使用的用户
- 数字知识管理爱好者 - 希望高效管理个人藏书或阅读清单
- 数据采集需求者 - 需要从网页抓取结构化数据
- 自动化探索者 - 对Make.com和GPT-4o应用有兴趣
可能不适合的情况
- 对技术配置完全不熟悉且不愿学习的用户
- 对数据准确性有100%极致要求的场景
- 每月处理量极小,手动录入成本更低的用户
常见问题
为什么要用截图而不是直接抓取网页?
豆瓣等网站有反爬机制,直接抓取困难。通过截图+GPT-4o多模态识别,可以绕过技术限制,且对任何网页都适用。
HCTI免费额度够用吗?
每月50次免费截图,对于个人图书管理场景通常足够。如需大量使用可考虑付费计划。
识别准确率如何?
根据测试,GPT-4o识别准确率很高,但对于复杂字母或特殊排版仍可能有细微错误,建议重要数据人工复核。
可以用于其他网站吗?
可以!只需调整提示词,就能应用于商品价格监控、股票走势分析、招聘信息抓取等场景。
下一步
学会了基础工作流后,你可以尝试:
- 添加豆瓣评分筛选,自动标记高分书籍
- 集成阅读进度追踪
- 添加定时任务监控书籍价格变化
- 扩展到其他数据采集场景
有问题欢迎在评论区留言交流!
常见问题
- 为什么要用截图而不是直接抓取网页?
- 豆瓣等网站有反爬机制,直接抓取困难。通过截图+GPT-4o多模态识别,可以绕过技术限制,且对任何网页都适用。
- HCTI免费额度够用吗?
- 每月50次免费截图,对于个人图书管理场景通常足够。如需大量使用可考虑付费计划。
- 识别准确率如何?
- 根据测试,GPT-4o识别准确率很高,但对于复杂字母或特殊排版仍可能有细微错误,建议重要数据人工复核。
- 可以用于其他网站吗?
- 可以!只需调整提示词,就能应用于商品价格监控、股票走势分析、招聘信息抓取等场景。