Make教程:Firecrawl全站抓取+AI自动生成博客文章实战
利用Firecrawl的map和scrape功能批量抓取网站内容,结合Make.com和大模型自动生成图文并茂的博客文章,实现内容引流自动化。
准备好开始自动化了吗?
使用 Make.com 构建此工作流 — 入门版永久免费。
概述
本教程深入探讨如何利用Firecrawl的数据采集能力与Make.com的自动化工作流,结合大语言模型实现全自动博客文章撰写与引流。
该方案能够高效抓取网站内容,智能转化并生成图文并茂的Markdown格式文章:
- 全站扫描 - 使用Firecrawl的map功能获取所有子链接
- 内容抓取 - scrape端点提取干净的Markdown内容
- AI处理 - 大模型翻译、去推广、格式化
- 自动存储 - 保存到Notion知识库
- 定时发布 - 每日固定数量分批次发布
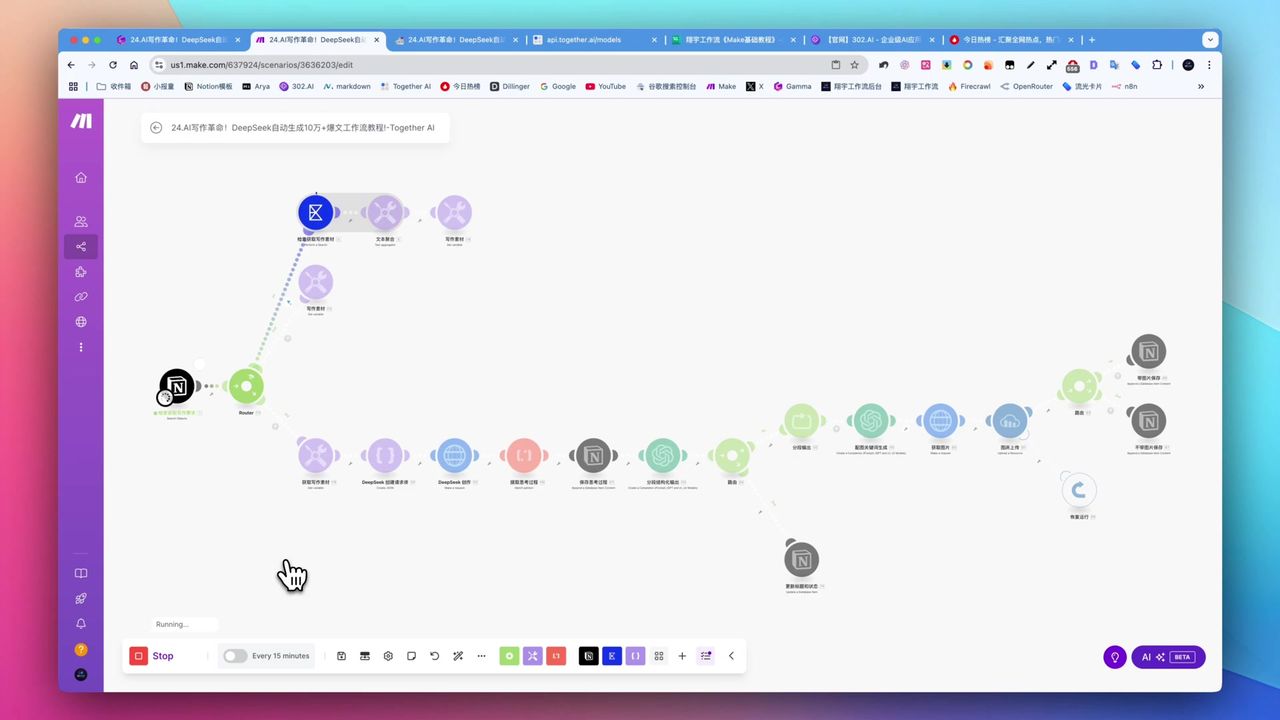
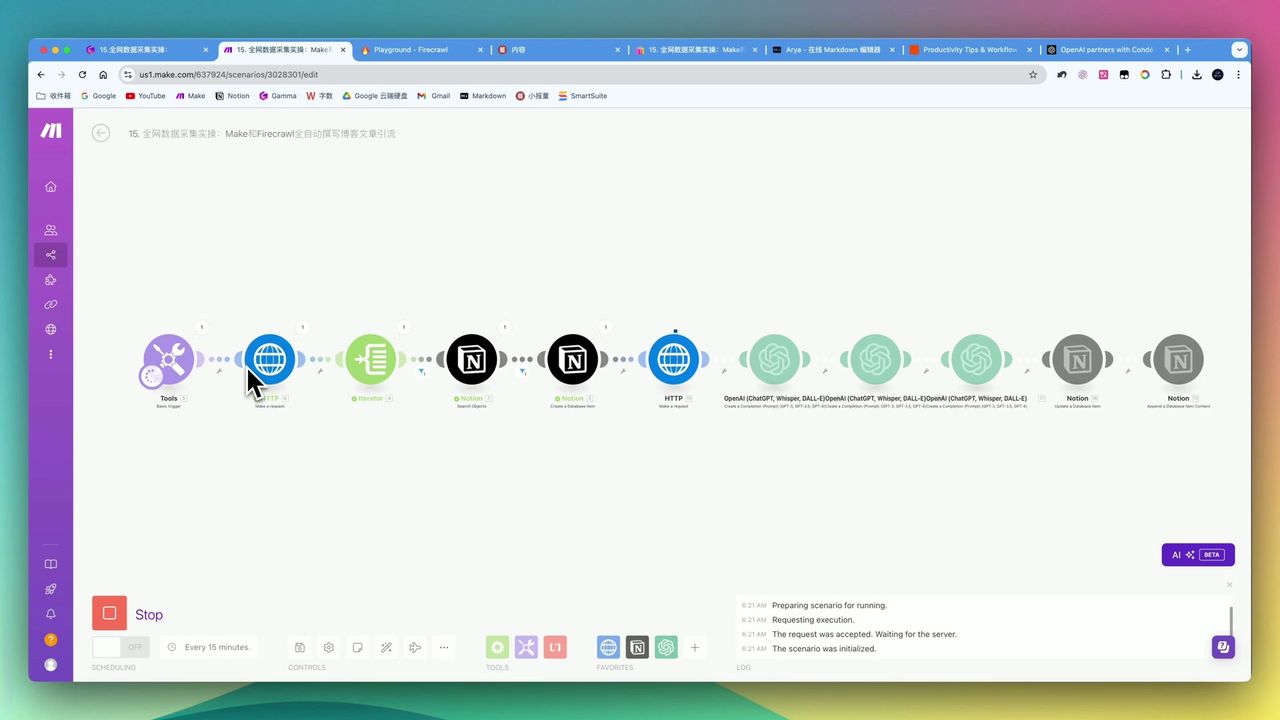 完整工作流:Firecrawl抓取 → 大模型处理 → Notion存储
完整工作流:Firecrawl抓取 → 大模型处理 → Notion存储
核心决策因素
在选择AI内容自动化方案时,需要关注:
- 数据采集能力 - 是否支持单页、全站及子链接深度抓取
- 内容处理转化 - 能否进行翻译、提炼、格式化和图文混排
- 自动化程度 - 是否支持批量处理和定时发布
- 成本与部署 - 免费额度、开源选项和本地部署能力
技术规格参考
| 规格 | 值 | 备注 |
|---|---|---|
| Firecrawl在线版免费额度 | 500点数/月 | 约500页面,个人需求通常足够 |
| Jina Reader API免费额度 | 100万请求 | 参考对比 |
| map功能抓取示例 | 3,553篇 | Zapier博客,速度极快 |
| HTTP请求默认超时 | 40秒 | 可能不够 |
| HTTP请求推荐超时 | 300秒 | 适用于耗时操作 |
| LLM处理博客Token | 4,096 | 适用于较长文章 |
| LLM处理小红书Token | 1,000 | 适用于短内容 |
| API速率限制错误码 | 429 | 需要控制请求频率 |
前置准备
在开始之前,请确保准备好:
- Make.com 账号(免费注册)
- Firecrawl API密钥(firecrawl.dev)
- OpenAI API密钥
- Notion 账号和数据库
Firecrawl核心功能
Firecrawl是专为AI设计的网页抓取工具,提供两个核心端点:
Map端点 - 全站扫描
快速获取网站下所有子链接,无需逐页抓取。
 3,553篇Zapier博客文章链接,瞬间获取
3,553篇Zapier博客文章链接,瞬间获取
特点:
- 速度极快,秒级完成
- 返回所有子链接列表
- 支持URL模式过滤
Scrape端点 - 内容提取
将网页转换为干净的Markdown格式,包含图片链接。
输出内容:
- 纯净Markdown文本
- 保留图片URL
- 去除广告和导航元素
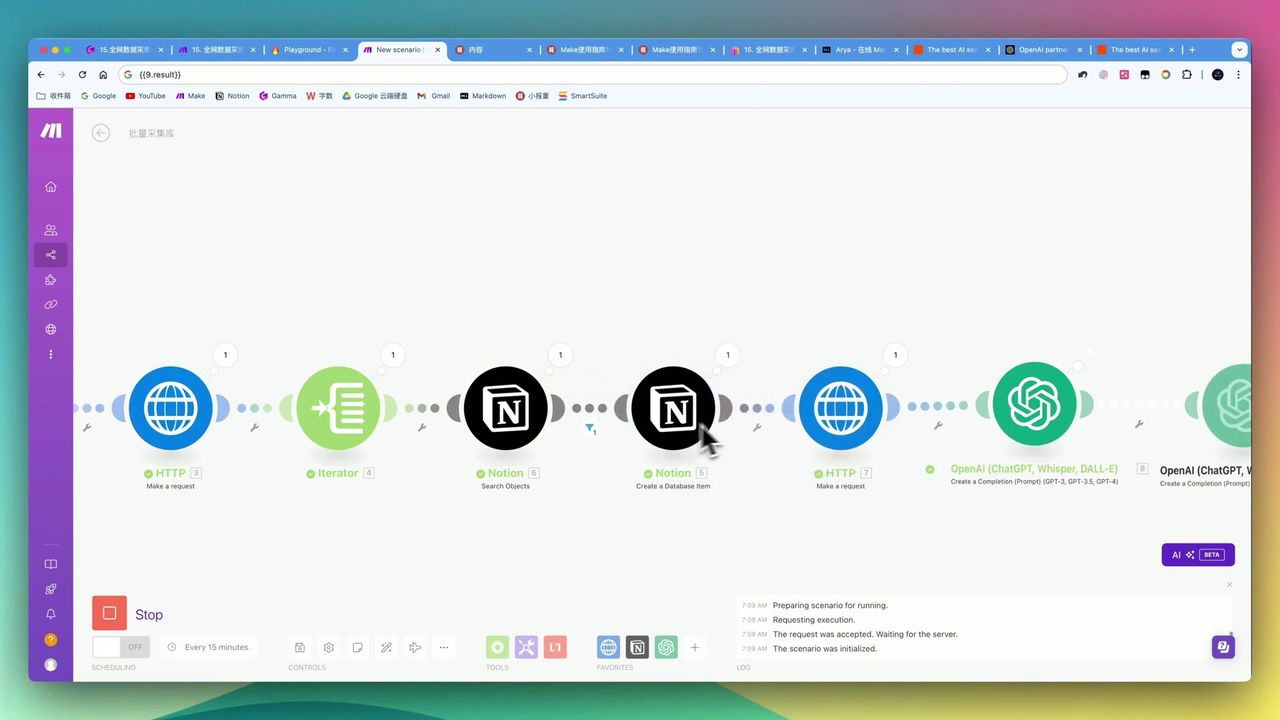
工作流架构
 完整的自动化工作流逻辑结构
完整的自动化工作流逻辑结构
核心模块
- Basic Trigger - 输入目标网址
- HTTP (Map) - 调用Firecrawl获取所有子链接
- Iterator - 遍历链接列表
- HTTP (Scrape) - 逐个抓取页面内容
- OpenAI - 翻译、去推广、格式化
- Notion - 保存生成的文章
Step 1: 配置Firecrawl Map请求
在Make中添加HTTP模块,调用Firecrawl的map端点:
请求配置:
- URL:
https://api.firecrawl.dev/v0/map - Method: POST
- Headers:
Authorization: Bearer {{your_api_key}} - Body:
{
"url": "{{target_website_url}}"
}Step 2: 配置内容抓取
使用Iterator遍历链接列表,逐个调用scrape端点:
请求配置:
- URL:
https://api.firecrawl.dev/v0/scrape - Method: POST
- Body:
{
"url": "{{current_link}}",
"formats": ["markdown"]
}注意:将超时时间设置为300秒,避免复杂页面抓取超时。
Step 3: 配置大模型处理
使用GPT-4o对抓取内容进行处理:
提示词设计:
请将以下英文内容翻译成中文,并进行以下处理:
1. 去除所有推广和引流内容
2. 保持Markdown格式
3. 保留所有图片链接
4. 生成适合博客发布的文章
原文内容:
{{scraped_markdown}}关键参数:
- Model: gpt-4o
- Max Tokens: 4096
Step 4: 智能防重与存储
配置Notion搜索模块,避免重复抓取:
- 搜索Notion数据库中是否已存在该URL
- 使用Router判断:存在则跳过,不存在则保存
- 将处理后的文章保存到Notion
注意:Notion中保存网址时,建议使用”文本”类型字段,避免非标准URL导致错误。
Step 5: 定时批量发布
通过日期公式实现每日固定数量发布:
实现方式:
- 在Notion中添加”发布日期”公式字段
- 设置每日发布数量(如10篇)
- Make定时任务筛选当天待发布文章
这样可以:
- 避免系统过载
- 保持内容持续更新
- 控制发布节奏
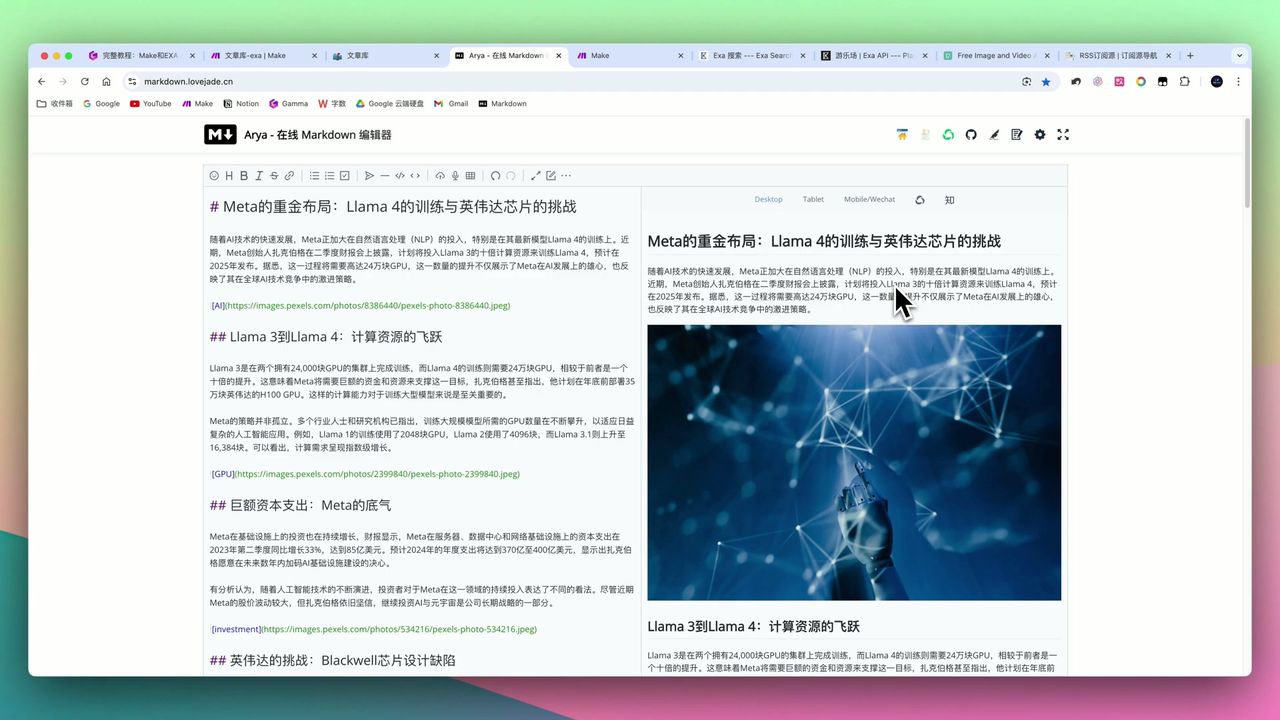
最终效果
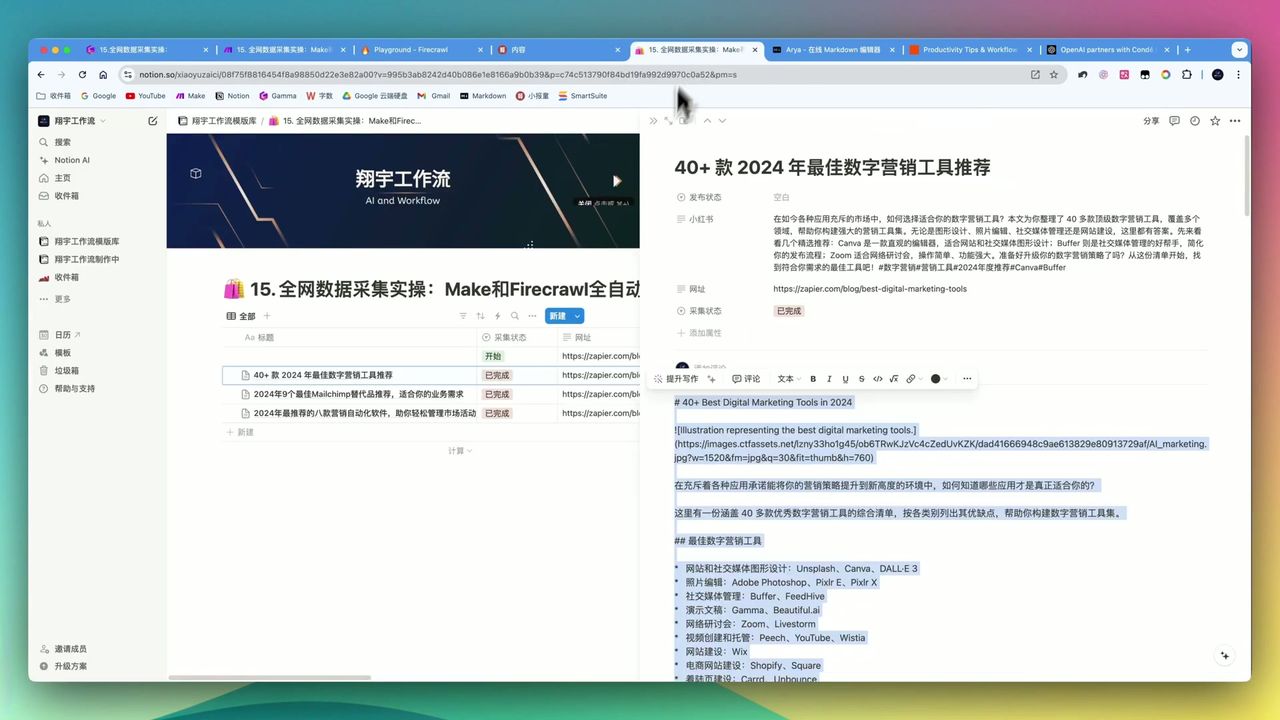
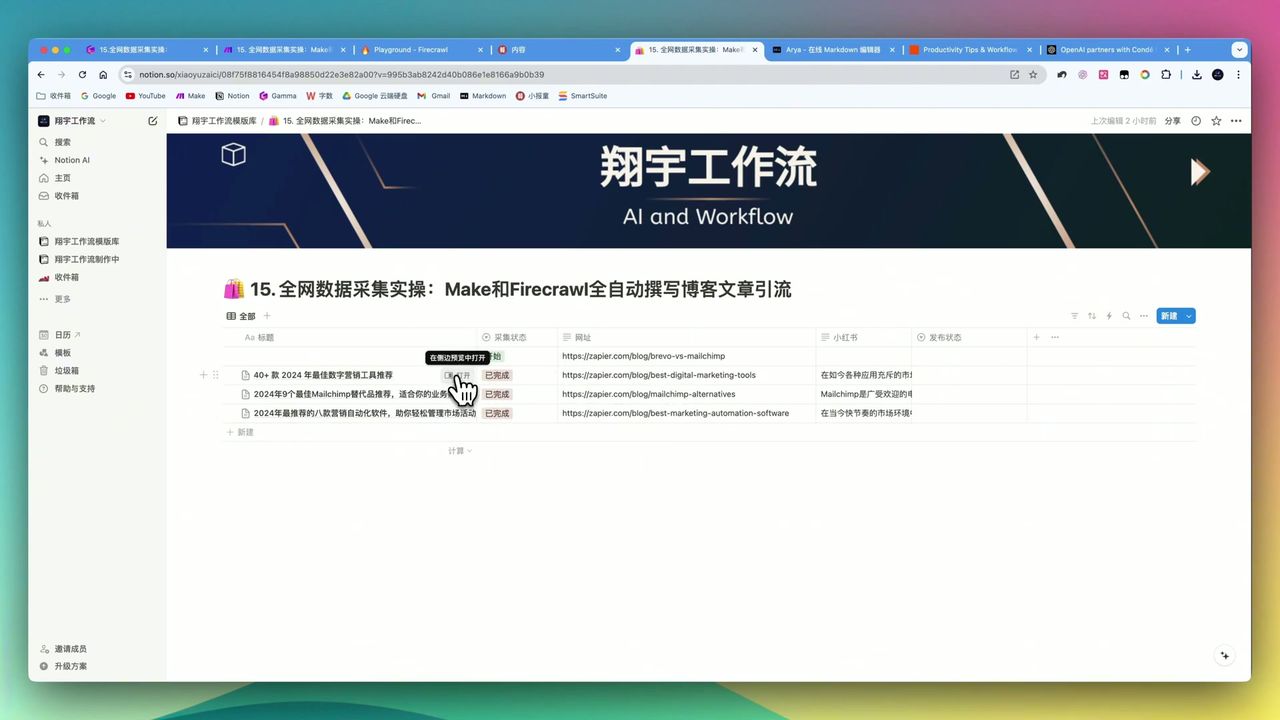 Firecrawl + 大模型生成的图文并茂博客文章
Firecrawl + 大模型生成的图文并茂博客文章
工作流运行后,你将获得:
- 图文并茂的Markdown格式文章
- 自动翻译和去推广处理
- 所有内容自动保存到Notion
- 支持批量和定时发布
注意事项
在搭建过程中需要注意:
-
内容后期处理 - 需明确指示大模型去除原文推广内容
-
Markdown格式微调 - 粘贴到编辑器时可能出现额外格式符(如两个星号),需手动删除
-
反爬机制 - 部分网站有严格反爬,Firecrawl可能抓取失败
-
JSON结构敏感 - 多余空格或非预期字符可能导致HTTP请求解析失败
-
大规模处理压力 - 批量处理数千篇内容时,建议分批次处理避免系统过载
-
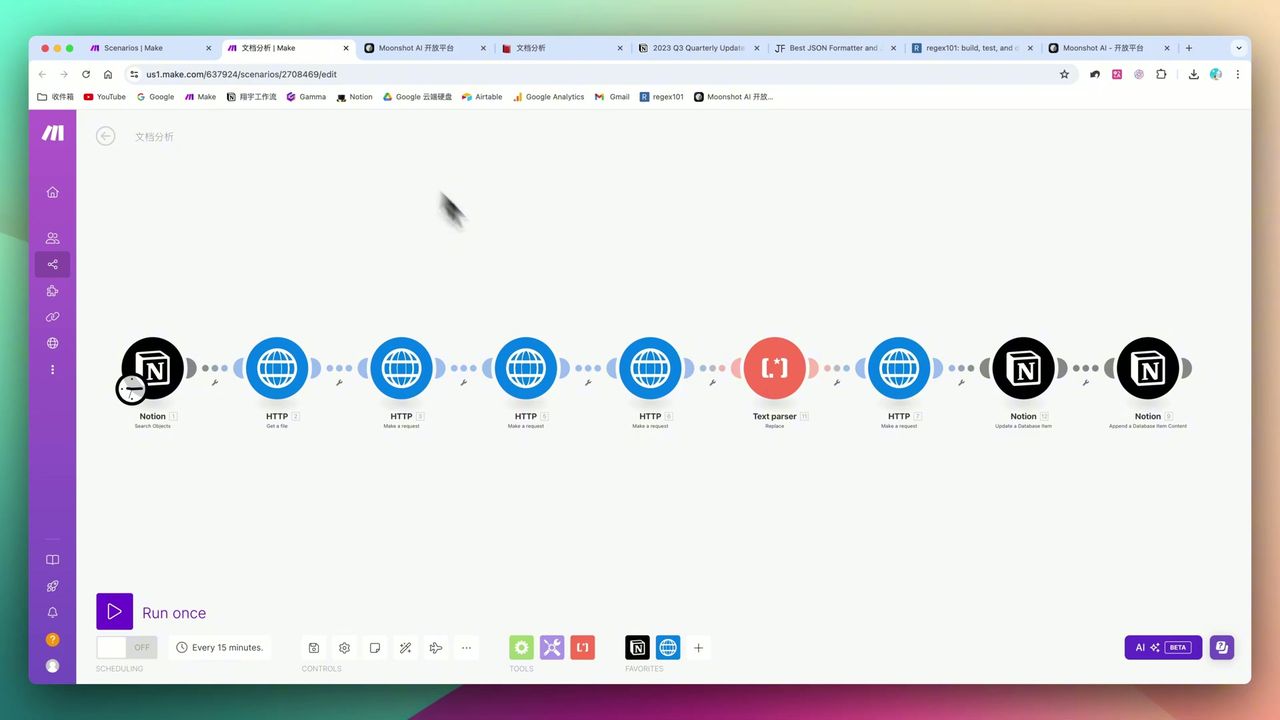
提示词精度 - 大模型模块配置需精确,特别是JSON输出格式指示
 大语言模型模块报错示例,注意提示词配置
大语言模型模块报错示例,注意提示词配置
适用场景
推荐使用的用户
- 内容创作者 - 希望大幅提升创作效率,保持更新频率
- 数字营销人员 - 通过高质量SEO文章进行引流
- 行业研究者 - 批量抓取特定领域网站进行结构化归档
- 降低人力成本的企业 - 用AI替代部分人工内容生产
可能不适合的情况
- 对API配置完全不熟悉的用户
- 对内容原创性有极高要求的用户
- 仅需简单文本抓取的用户
- 追求绝对零错误零干预的用户
常见问题
Firecrawl的免费额度够用吗?
在线版每月500点数(约500页面),个人非大规模需求通常足够。也支持开源自部署,无额度限制。
能抓取所有网站吗?
大部分网站可以,但对于有严格反爬机制的网站可能会失败。建议先小规模测试。
生成的文章质量如何?
经过大模型翻译和润色,文章图文并茂、格式规范,但核心内容源自抓取,需注意版权问题。
如何避免重复抓取同一网址?
工作流通过Notion搜索模块实现智能防重,自动跳过已采集的网址。
下一步
学会了基础工作流后,你可以尝试:
- 添加更多内容来源网站
- 集成小红书笔记生成模块
- 添加自定义引流广告植入
- 设置多语言翻译输出
有问题欢迎在评论区留言交流!
常见问题
- Firecrawl的免费额度够用吗?
- 在线版每月500点数(约500页面),个人非大规模需求通常足够。也支持开源自部署,无额度限制。
- 能抓取所有网站吗?
- 大部分网站可以,但对于有严格反爬机制的网站可能会失败。建议先小规模测试。
- 生成的文章质量如何?
- 经过大模型翻译和润色,文章图文并茂、格式规范,但核心内容源自抓取,需注意版权问题。
- 如何避免重复抓取同一网址?
- 工作流通过Notion搜索模块实现智能防重,自动跳过已采集的网址。