Make教程:用Kimi API + Make打造超长PDF文档自动分析机器人
利用Kimi的128K超长上下文能力,结合Make.com自动解析PDF财报、书籍等长文档,提取核心观点并回写Notion知识库。
准备好开始自动化了吗?
使用 Make.com 构建此工作流 — 入门版永久免费。
概述
对于需要处理中文长文档(如财报、书籍)但受限于OpenAI访问困难或成本过高的用户,Kimi API结合Make.com是一个极具性价比的替代方案。
该工作流利用Kimi强大的128K+上下文能力,实现长文档的自动分析:
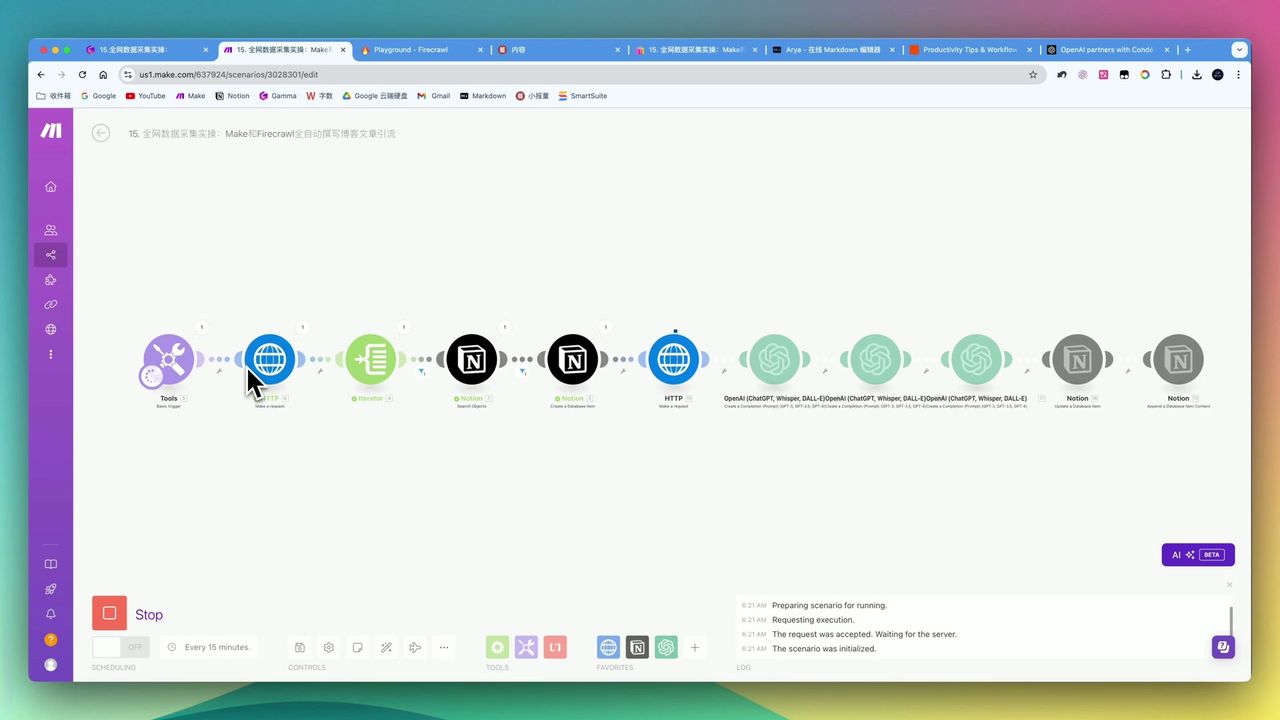
- 触发任务 - Notion数据库状态变更触发
- 上传文件 - 将PDF上传到Kimi获取File ID
- 解析内容 - 调用解析接口获取文本内容
- AI分析 - 发送给Kimi进行总结提炼
- 回写结果 - 将核心观点保存到Notion
- 清理文件 - 删除已处理的文件防止堆积
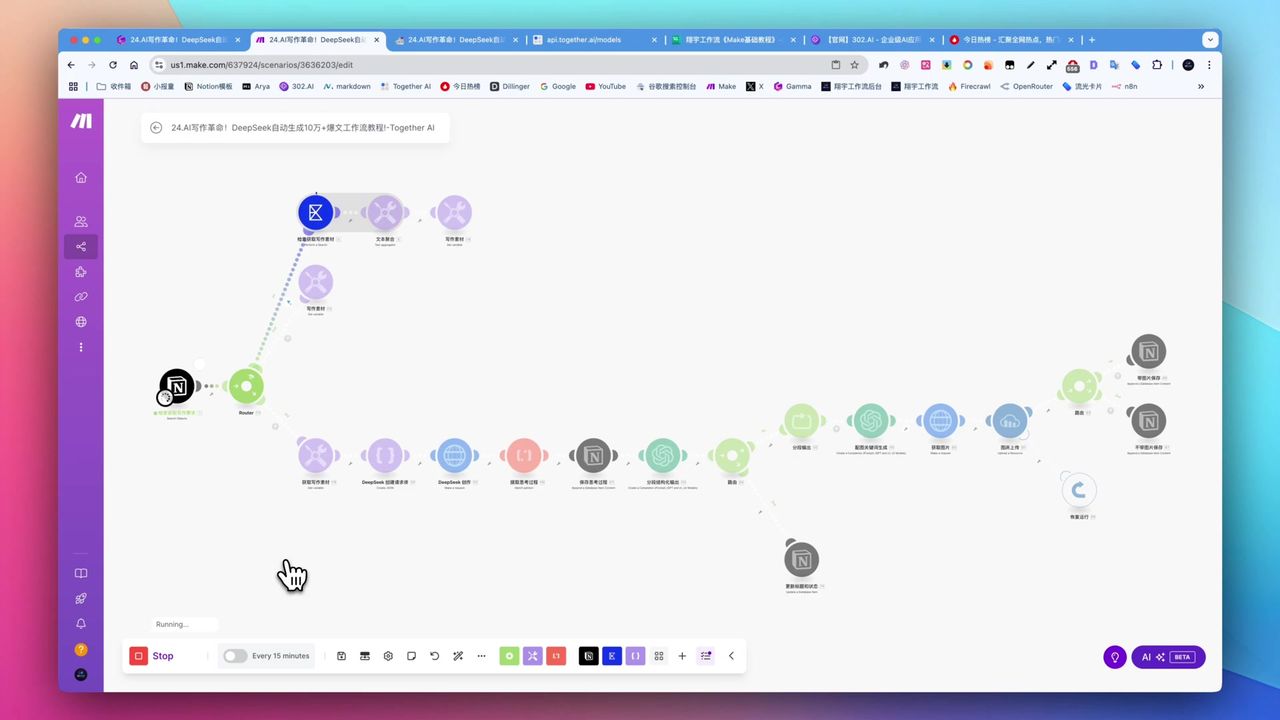
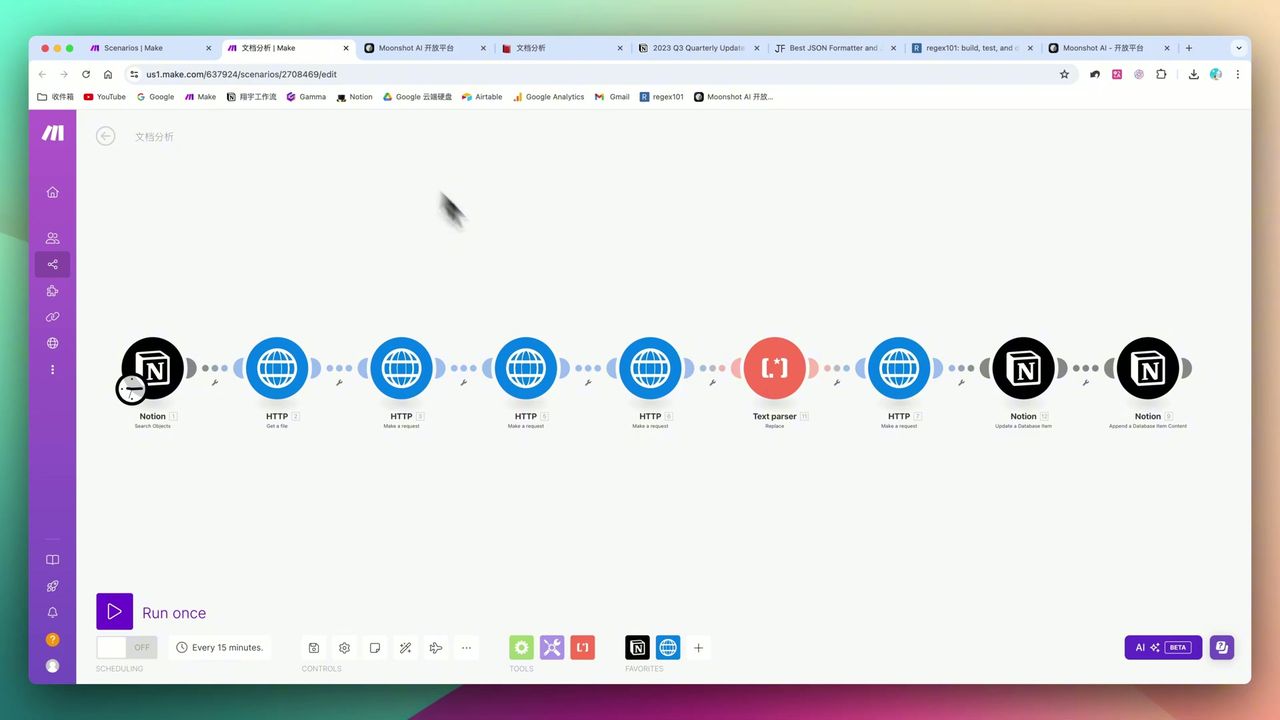 完整的8步自动化工作流架构
完整的8步自动化工作流架构
核心决策因素
在选择AI长文档处理方案时,需重点考量:
- 长文本吞吐量 - 能否一次性读取几十页PDF而不丢失信息
- API易用性与成本 - 接口文档是否清晰,Token价格是否亲民
- 容错机制 - 面对特殊字符、网络超时等异常的处理能力
- 数据结构化能力 - 能否将PDF内容转化为可用的JSON格式
技术规格参考
| 关键指标 | 规格 | 备注 |
|---|---|---|
| Kimi模型上下文 | 8K/32K/128K | 推荐使用128K处理长文档 |
| Notion上传限制 | 5MB | 免费版限制,大文件用Google Drive |
| Kimi文件存储上限 | 100个文件 | 必须配置删除步骤 |
| HTTP超时设置 | 300秒 | 处理长文本建议延长 |
| 状态码校验 | 200 | 建议添加Filter过滤 |
| API鉴权方式 | Bearer Token | Header添加Authorization |
前置准备
在开始之前,请确保准备好:
- Make.com 账号(免费注册)
- Kimi API密钥(kimi.moonshot.cn)
- Notion 账号和数据库
Notion数据库结构
创建PDF管理数据库,包含以下字段:
- 文件 (Files & Media) - 上传PDF文件
- 状态 (Select) - Start/Processing/Done
- 分析结果 (Text) - AI提取的核心观点
- 文件链接 (URL) - PDF的访问链接
为什么选择Kimi API
相比OpenAI,Kimi在处理中文长文档方面具有独特优势:
| 对比项 | Kimi | OpenAI |
|---|---|---|
| 上下文窗口 | 128K(未来200K+) | 128K(GPT-4 Turbo) |
| 中文能力 | 原生优化 | 一般 |
| 国内访问 | 直接访问 | 需要代理 |
| API成本 | 相对较低 | 较高 |
| Make集成 | 需HTTP模块 | 有原生模块 |
工作流架构
整个工作流分为三个核心阶段:
阶段一:文件上传
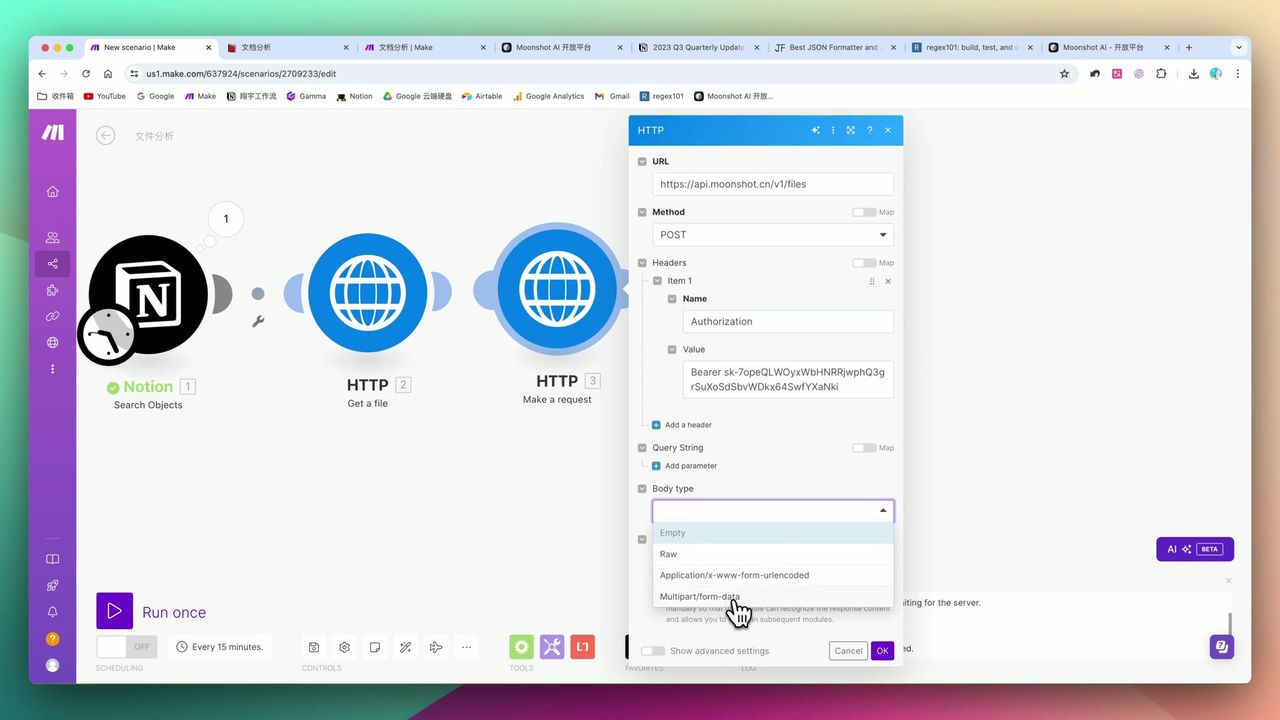 Multipart/form-data配置详解
Multipart/form-data配置详解
使用HTTP模块上传PDF到Kimi:
请求配置:
- URL:
https://api.moonshot.cn/v1/files - Method: POST
- Content-Type: multipart/form-data
- Headers:
Authorization: Bearer {{api_key}}
上传成功后获取file_id,用于后续解析。
阶段二:内容解析与清洗
获取File ID后,调用解析接口获取PDF文本内容。
关键步骤:Text Parser清洗
 使用正则表达式清洗原始文本
使用正则表达式清洗原始文本
PDF解析出的原始文本常包含:
- 换行符
\n - 特殊括号
[]、{} - 多余空格
这些字符直接放入JSON会破坏数据结构,必须使用正则替换清洗。
阶段三:AI分析与回写
 构建128K上下文模型的Prompt
构建128K上下文模型的Prompt
将清洗后的文本发送给Kimi进行分析:
Prompt设计:
{
"model": "moonshot-v1-128k",
"messages": [
{
"role": "system",
"content": "你是一个专业的文档分析专家,擅长从长篇报告中提取核心观点。"
},
{
"role": "user",
"content": "请从以下文档中提取10个核心观点:\n\n{{cleaned_text}}"
}
]
}阶段四:文件清理(关键)
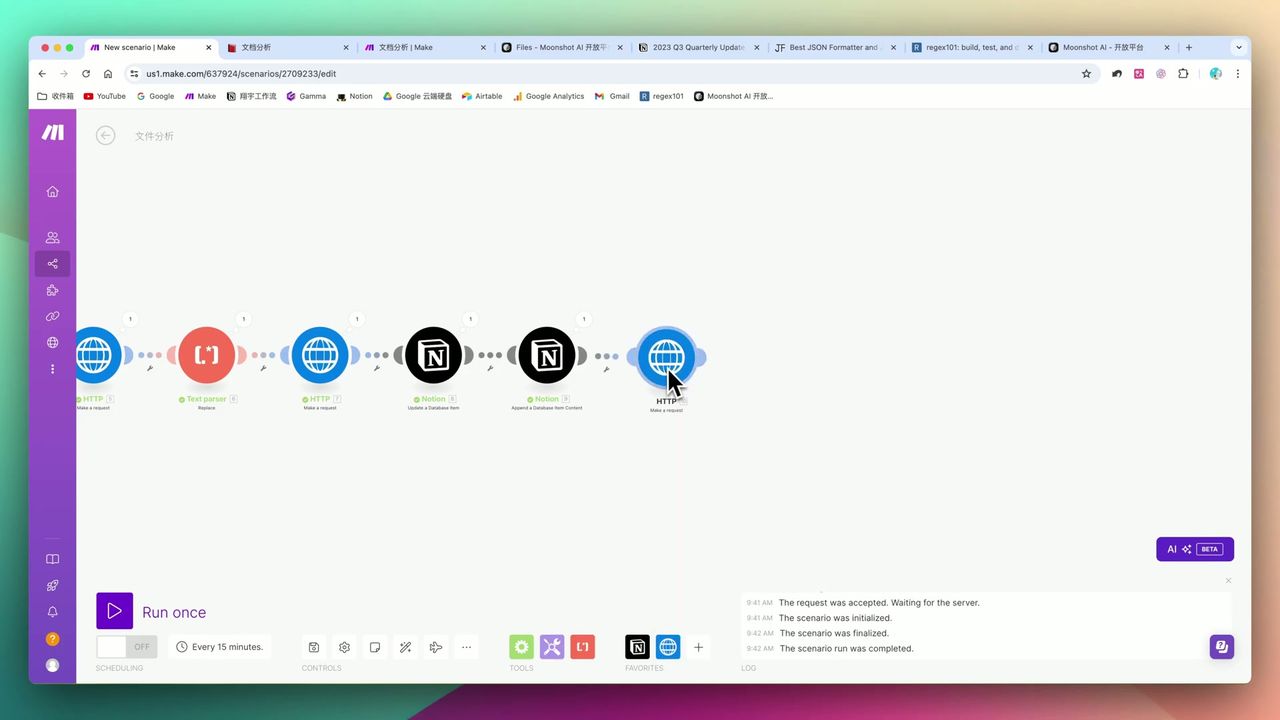 必须配置的文件删除步骤
必须配置的文件删除步骤
Kimi API有100个文件的硬性上限,必须配置删除步骤:
请求配置:
- URL:
https://api.moonshot.cn/v1/files/{{file_id}} - Method: DELETE
- Headers:
Authorization: Bearer {{api_key}}
重要:如果不设置删除步骤,运行100次后工作流将彻底瘫痪!
注意事项
在实操中容易遇到的”坑”:
-
JSON结构的”隐形杀手” - PDF解析的原始文本包含特殊字符,必须用Text Parser正则清洗
-
文件堆积陷阱 - Kimi有100个文件上限,必须配置”分析后删除”步骤
-
数据延迟与映射困难 - Make中如果上一步HTTP请求未运行,后续模块无法映射变量,需要”空跑”一次获取数据结构
-
Notion体积瓶颈 - 免费版仅支持5MB文件,大PDF需通过Google Drive绕道
-
HTTP超时 - 处理长文本建议将超时时间延长到300秒以上
实际效果
处理能力:
- 能够从30多页的英文特斯拉财报中,准确提取”财务概要”、“成本控制”等10个核心观点
处理效率:
- 相比人工阅读,机器处理仅需数分钟(取决于文件长度)
适用场景
推荐使用的用户
- 金融从业者/研究员 - 每天阅读大量研报获取关键信息
- OpenAI受限用户 - 需要高质量中文长文本处理能力
- Notion重度用户 - 希望构建自动化知识库闭环
可能不适合的情况
- 对API、JSON、HTTP请求完全无概念的零基础用户
- 超大扫描件处理者(>50MB的图片PDF)
常见问题
为什么选择Kimi而不是OpenAI?
Kimi支持128K+超长上下文,中文处理能力强,国内可直接访问,API成本相对较低,适合处理长篇中文文档。
Kimi API有什么限制?
文件存储上限100个,超过会报错。必须在工作流中配置删除步骤,处理完成后及时清理文件。
为什么需要Text Parser清洗数据?
PDF解析出的原始文本常包含换行符、特殊字符,直接放入JSON会破坏数据结构导致API报错,必须用正则表达式清洗。
Notion上传文件有什么限制?
Notion免费版仅支持5MB文件上传,超大PDF需要通过Google Drive绕道触发。
下一步
学会了基础工作流后,你可以尝试:
- 添加OCR模块处理扫描版PDF
- 集成多语言翻译功能
- 添加批量处理队列
- 设置定时任务自动处理新文件
有问题欢迎在评论区留言交流!
常见问题
- 为什么选择Kimi而不是OpenAI?
- Kimi支持128K+超长上下文,中文处理能力强,国内可直接访问,API成本相对较低,适合处理长篇中文文档。
- Kimi API有什么限制?
- 文件存储上限100个,超过会报错。必须在工作流中配置删除步骤,处理完成后及时清理文件。
- 为什么需要Text Parser清洗数据?
- PDF解析出的原始文本常包含换行符、特殊字符,直接放入JSON会破坏数据结构导致API报错,必须用正则表达式清洗。
- Notion上传文件有什么限制?
- Notion免费版仅支持5MB文件上传,超大PDF需要通过Google Drive绕道触发。