Make教程:Jina Reader API实战 - 零代码打造新闻自动采集流
通过Make.com结合Jina Reader API和ChatGPT,解决RSS只有标题无正文的痛点,自动抓取全文并归档到Notion知识库。
准备好开始自动化了吗?
使用 Make.com 构建此工作流 — 入门版永久免费。
概述
本工作流展示了一套高效的信息自动化解决方案。通过结合Make.com的流程编排、Jina Reader API的网页转Markdown能力以及ChatGPT的总结能力,完美解决了传统RSS订阅”只有标题无正文”的痛点。
整个流程如下:
- 获取链接 - 通过RSS订阅获取最新文章URL
- 获取内容 - 使用Jina Reader抓取全文并清洗
- 处理内容 - GPT翻译标题并生成摘要
- 存储内容 - 自动归档到Notion数据库
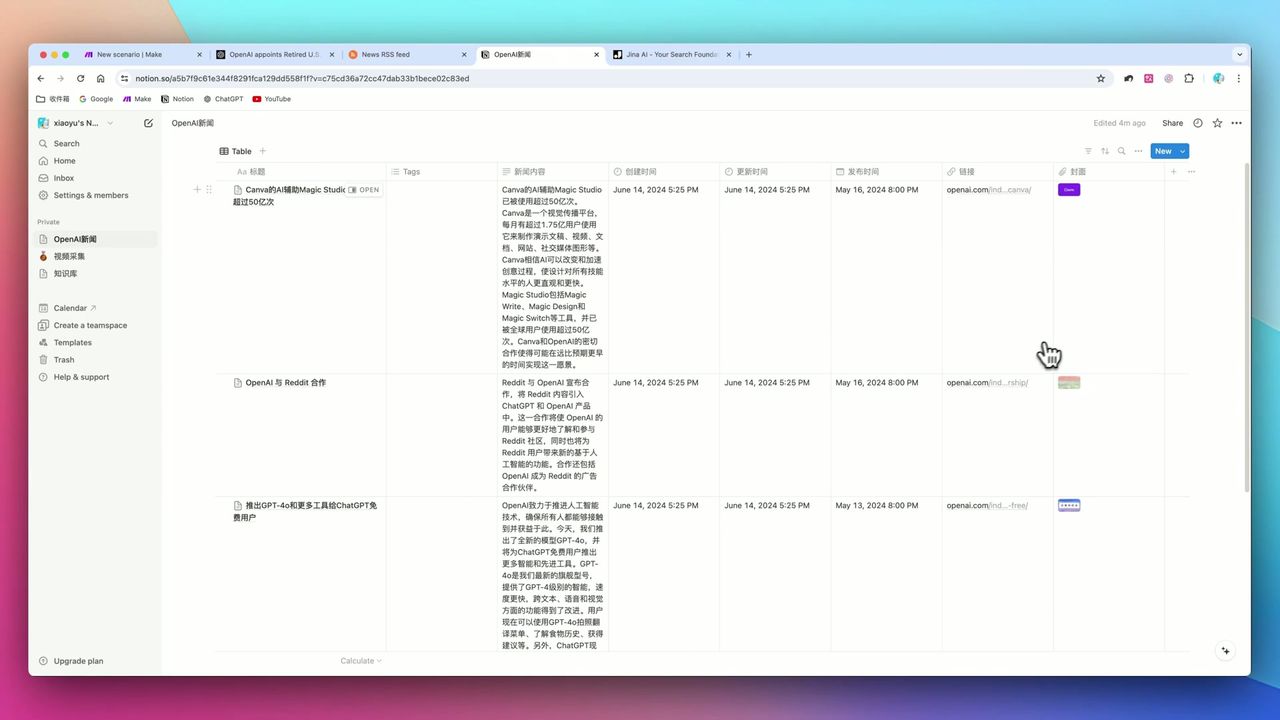 自动生成的新闻数据库,包含封面图、标题和摘要
自动生成的新闻数据库,包含封面图、标题和摘要
核心决策因素
构建此类自动化工作流时,需要关注:
- 全文抓取能力 - 能否绕过反爬机制,将HTML转换为干净文本
- 数据结构化 - 能否将网页内容转化为数据库可读的格式
- 运行稳定性 - 各节点连接是否稳定,是否容易过期
- 成本效益 - 涉及的SaaS工具总拥有成本
技术配置参考
| 配置项 | 设定值 | 备注 |
|---|---|---|
| 核心工具 | Make.com + Jina Reader + Notion | 自动化中枢/解析器/数据库 |
| 数据源 | RSS.app 或 RSSHub | 将网页转化为RSS Feed |
| AI模型 | GPT-3.5 | 用于翻译和生成摘要 |
| 最大Token数 | 1,000 | 控制成本 |
| Jina模式 | Reader Mode | 将URL转为LLM友好文本 |
| Jina关键Header | x-respond-with: json | 强制返回JSON格式 |
| 缓存设置 | x-no-cache: true | 确保获取最新内容 |
| HTTP请求方式 | GET | 调用Jina API |
前置准备
在开始之前,请确保准备好:
- Make.com 账号(免费注册)
- OpenAI API 密钥
- Notion 账号和数据库
- RSS订阅源(可用RSS.app生成,或使用免费的RSSHub)
Notion数据库字段设置
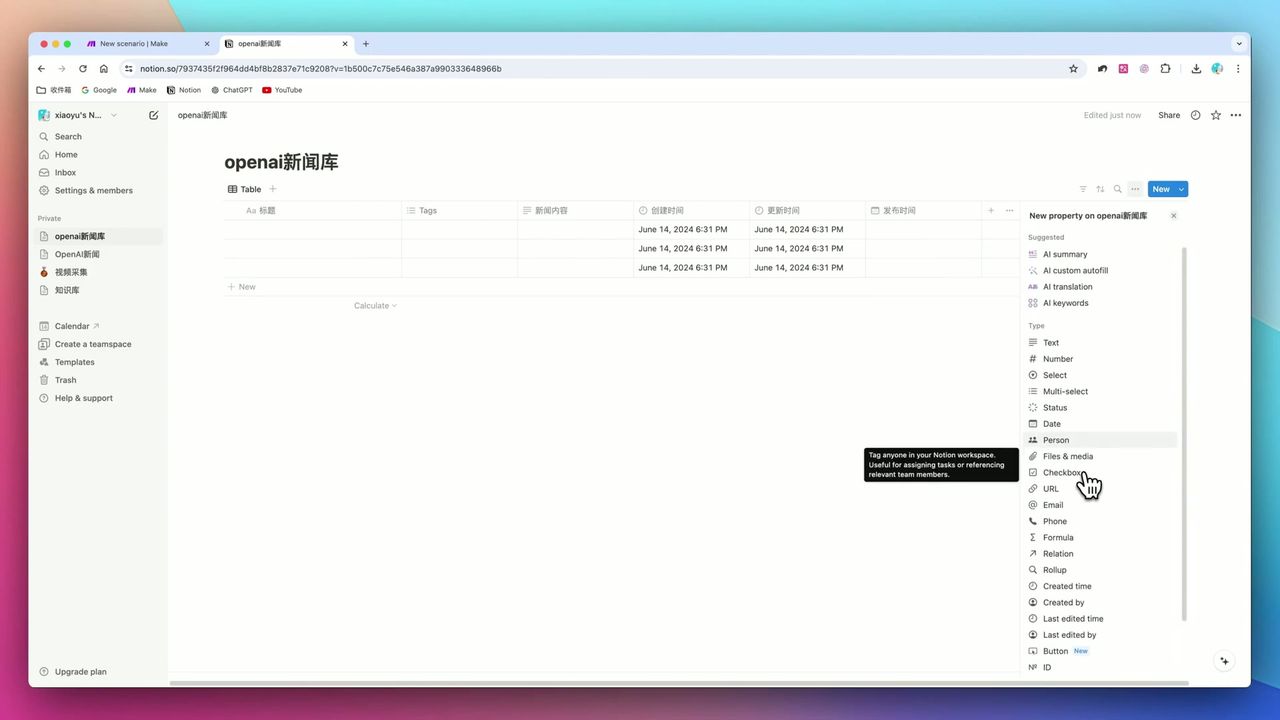 必须具备的字段:Title、Date、URL、Cover、Content
必须具备的字段:Title、Date、URL、Cover、Content
在Notion中创建数据库,包含以下字段:
- Title (Title) - 文章标题
- Date (Date) - 发布时间
- URL (URL) - 原文链接
- Cover (Files & Media) - 封面图片
- Content (Text) - AI生成的摘要
Step 1: 配置RSS数据源
首先需要获取目标网站的RSS订阅源。
方式一:使用RSS.app(付费,约$10/月)
- 输入网站URL自动生成RSS Feed
- 操作简单,适合非技术用户
方式二:使用RSSHub(免费,需部署)
- 开源项目,支持众多网站
- 需要一定技术能力部署
在Make中添加RSS模块,获取最新文章列表。
Step 2: 配置Jina Reader API
这是整个工作流的核心解法。
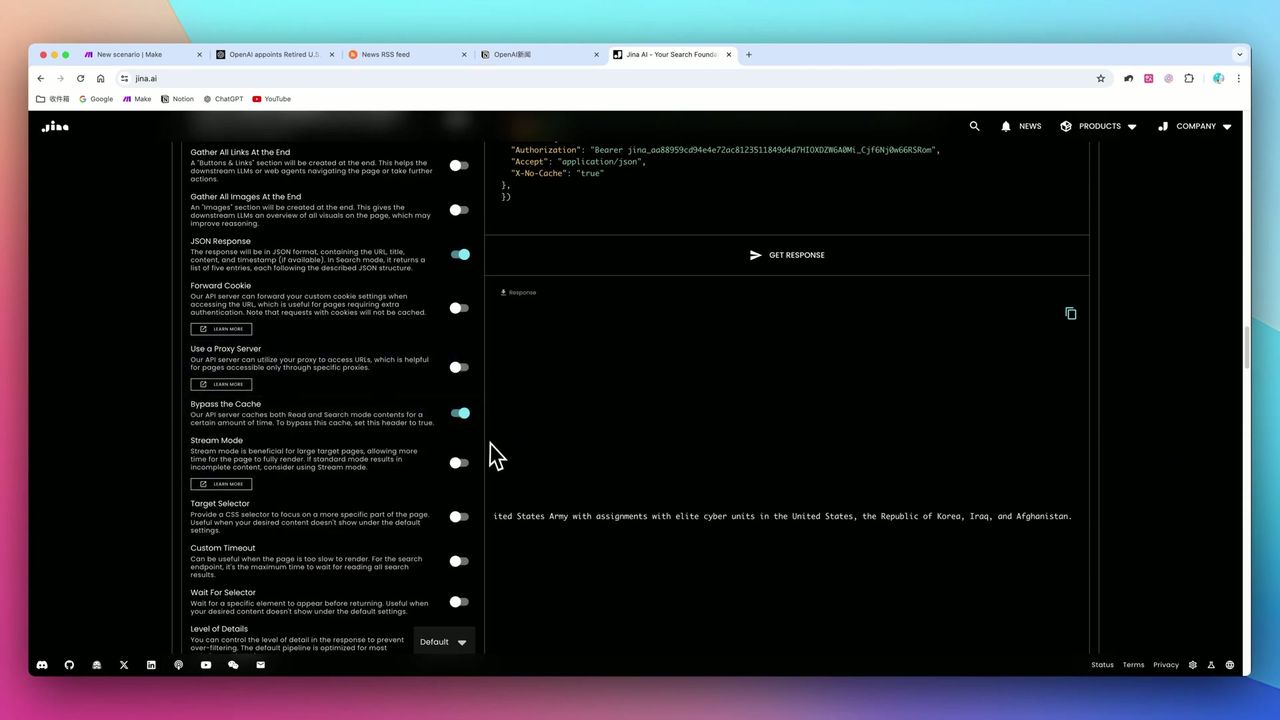 开启JSON响应和跳过缓存选项
开启JSON响应和跳过缓存选项
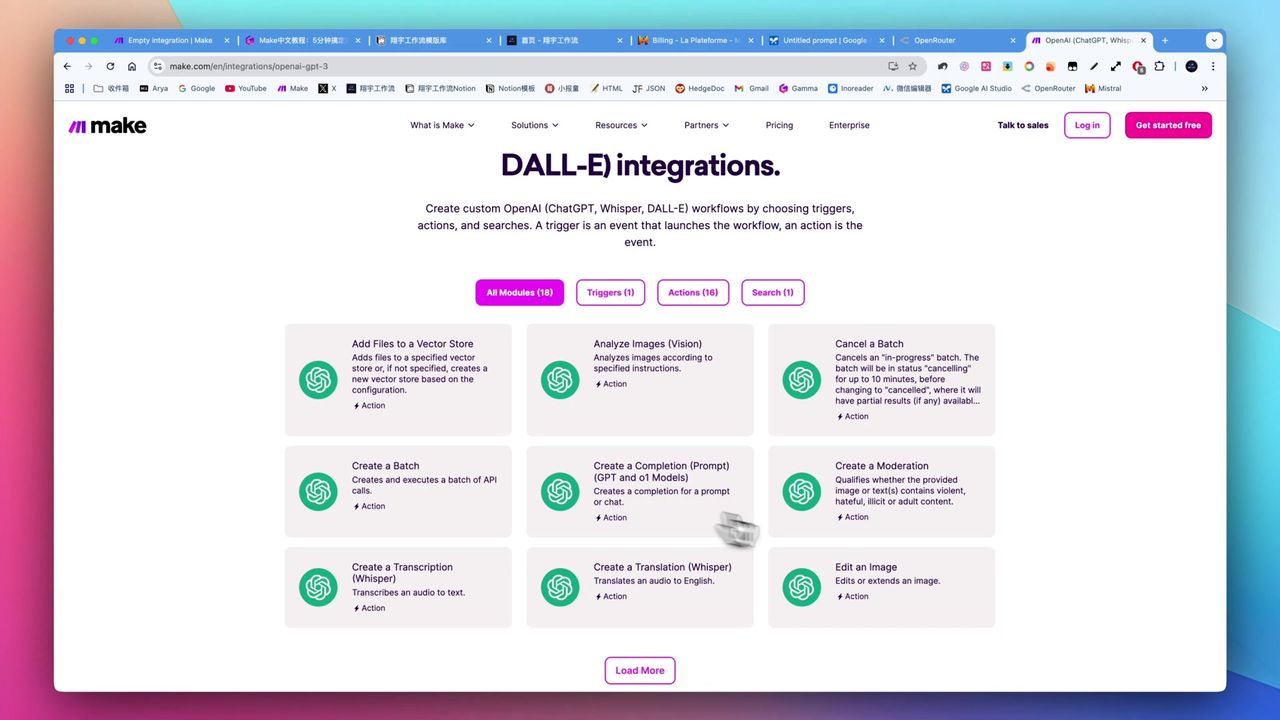
为什么需要Jina Reader?
传统爬虫配置复杂,而Jina直接将URL变成干净的文本。如果不使用,直接抓取的网页包含大量HTML标签:
- 极大浪费OpenAI的Token额度
- 干扰AI的理解能力
- 难以提取有效信息
配置HTTP模块:
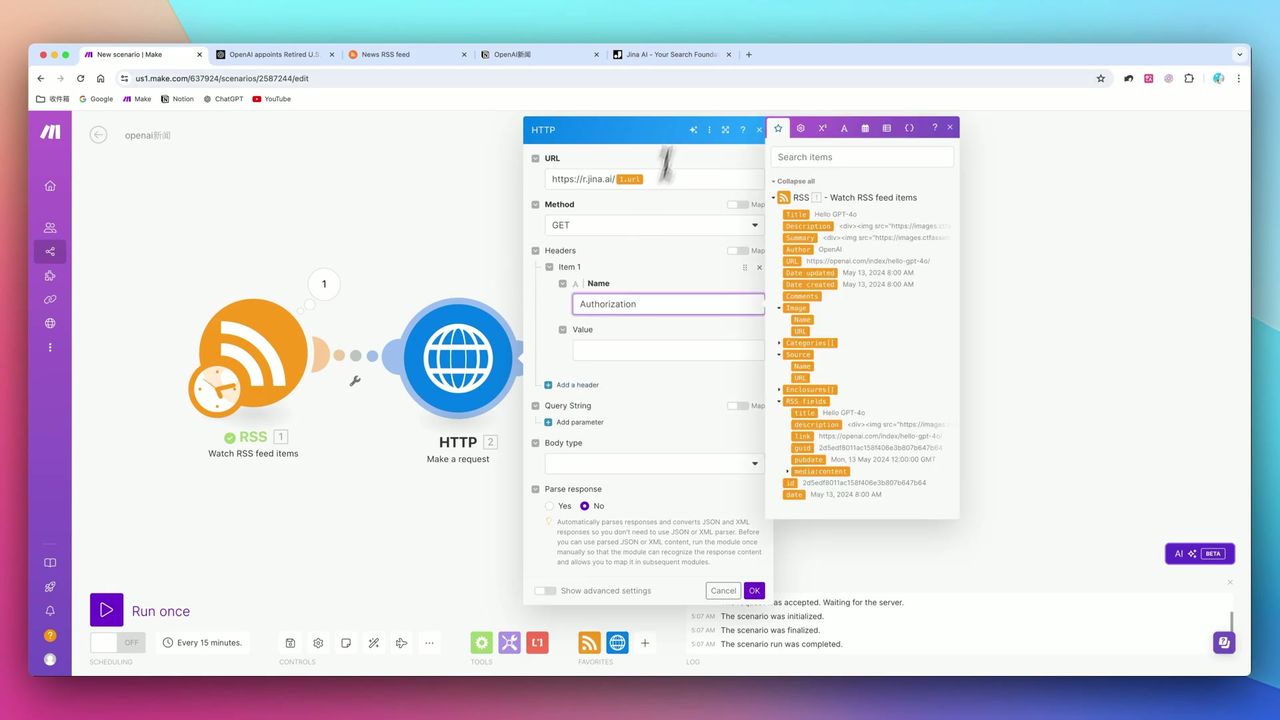 正确配置HTTP请求头调用Jina API
正确配置HTTP请求头调用Jina API
关键配置:
- URL:
https://r.jina.ai/{{原文URL}} - Method: GET
- Headers:
x-respond-with: json- 强制返回JSON格式x-no-cache: true- 跳过缓存获取最新内容
Step 3: 配置ChatGPT处理内容
使用GPT对抓取的内容进行翻译和摘要。
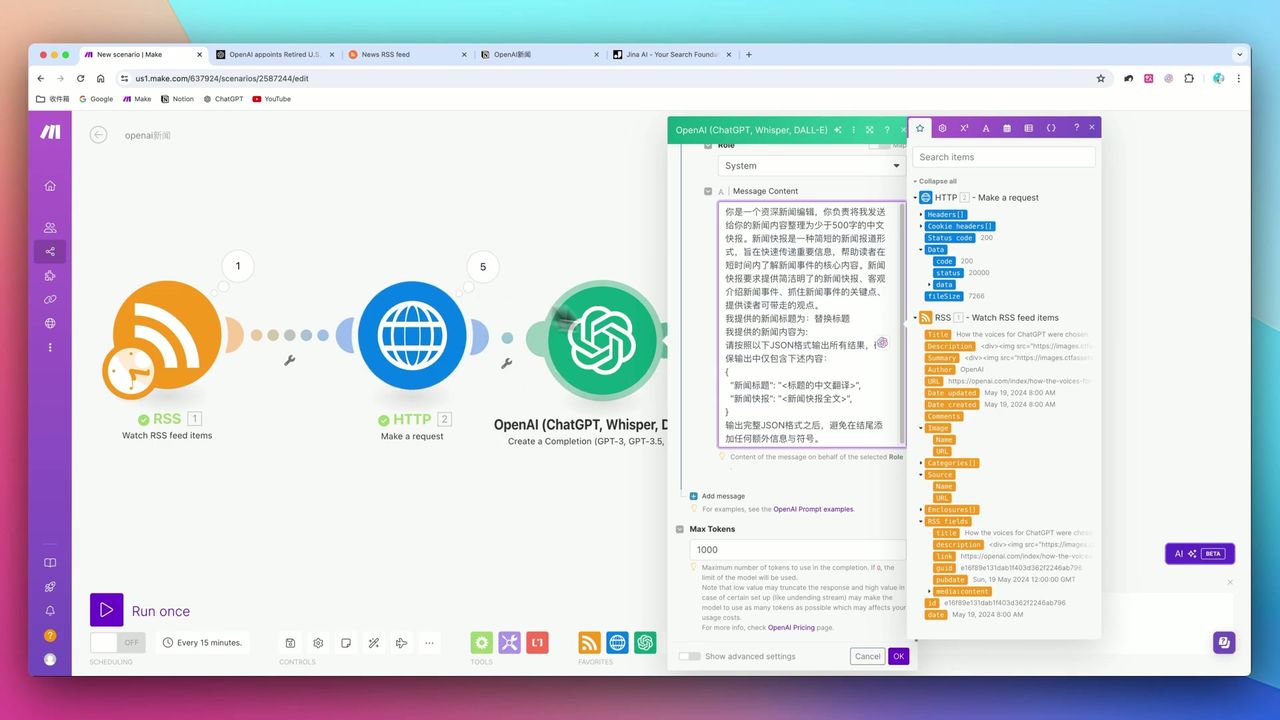 同时完成翻译、总结并输出JSON格式
同时完成翻译、总结并输出JSON格式
Prompt设计要点:
请对以下新闻内容进行处理:
1. 将标题翻译成中文
2. 生成100-150字的中文摘要
3. 提取关键词(3-5个)
输出JSON格式:
{"title": "中文标题", "summary": "摘要内容", "keywords": ["关键词1", "关键词2"]}
原文内容:
{{Jina返回的文本}}关键参数:
- Model: GPT-3.5(成本低,速度快)
- Max Tokens: 1,000(控制成本)
- Response Format: JSON Mode
Step 4: 存储到Notion
将处理后的内容写入Notion数据库。
添加Notion模块,映射字段:
- Title ← AI翻译的中文标题
- Date ← 原文发布时间
- URL ← 原文链接
- Cover ← 从Jina提取的图片URL
- Content ← AI生成的摘要
注意:如果原网站有防盗链设置,Notion可能无法正确显示封面图片。
注意事项
在实际部署时,需要注意以下潜在问题:
-
RSS工具成本 - RSS.app是付费工具,如果想免费需要使用RSSHub等开源方案
-
Make连接时效性 - Make与Notion的连接授权可能过期,需要定期刷新
-
HTML清洗重要性 - Jina的价值在于充当”清洗层”,没有它Token消耗会暴增
-
图片防盗链 - 部分网站图片有防盗链设置,保存到Notion封面时可能无法显示
适用场景
推荐使用的用户
- 运营人员 - 需要监控特定网站(如竞品官网)更新
- 研究员 - 建立个人知识库
- 内容策展人 - 自动收集行业资讯
- 分析师 - 竞品分析和情报监控
可能不适合的情况
- 对数据实时性要求极高(秒级)的用户
- 完全不愿支付任何API费用或SaaS订阅费的用户
- 需要抓取登录后才能访问内容的场景
常见问题
Jina Reader是免费的吗?
Jina Reader API有免费额度,足够个人使用和测试。如果是大规模抓取,需要关注用量限制。
为什么需要Jina Reader而不是直接抓取网页?
直接抓取的网页包含大量HTML标签,会浪费OpenAI的Token额度且干扰AI理解。Jina Reader充当清洗层,将网页转为干净的Markdown文本。
Make和Notion的连接会失效吗?
是的,Make与Notion的连接授权可能过期或需要刷新,这是长期运行中最容易导致工作流中断的原因,需要定期检查。
可以抓取任何网站吗?
大部分网站可以,但有些网站有反爬机制可能导致抓取失败。另外,图片可能因为防盗链设置无法在Notion中正确显示。
下一步
学会了基础工作流后,你可以尝试:
- 添加更多RSS源,扩展信息来源
- 设置定时触发,实现每日自动更新
- 添加分类标签,便于后续检索
- 尝试对接其他存储平台(如Airtable)
有问题欢迎在评论区留言交流!
常见问题
- Jina Reader是免费的吗?
- Jina Reader API有免费额度,足够个人使用和测试。如果是大规模抓取,需要关注用量限制。
- 为什么需要Jina Reader而不是直接抓取网页?
- 直接抓取的网页包含大量HTML标签,会浪费OpenAI的Token额度且干扰AI理解。Jina Reader充当清洗层,将网页转为干净的Markdown文本。
- Make和Notion的连接会失效吗?
- 是的,Make与Notion的连接授权可能过期或需要刷新,这是长期运行中最容易导致工作流中断的原因,需要定期检查。
- 可以抓取任何网站吗?
- 大部分网站可以,但有些网站有反爬机制可能导致抓取失败。另外,图片可能因为防盗链设置无法在Notion中正确显示。