Make教程:用Make.com + AI搭建小红书自动化内容工厂
基于Make.com结合Jina Reader和OpenAI,实现从选题发现到内容生成再到排版归档的全链路自动化,打造24/7内容生产机器。
准备好开始自动化了吗?
使用 Make.com 构建此工作流 — 入门版永久免费。
概述
对于追求极致效率的自媒体创作者,特别是专注于资讯搬运与二次加工的运营者来说,这套基于Make.com的工作流是一次重大升级。
它成功实现了从选题发现到内容生成再到排版归档的全链路自动化:
- 信息采集 - 通过Inoreader RSS订阅行业资讯
- 内容清洗 - 使用Jina Reader提取网页核心内容
- AI创作 - GPT-4o生成小红书风格笔记
- 结构化存储 - 自动归档到Notion数据库
一旦配置完成,它就是一个不知疲倦的24/7内容生产机器。
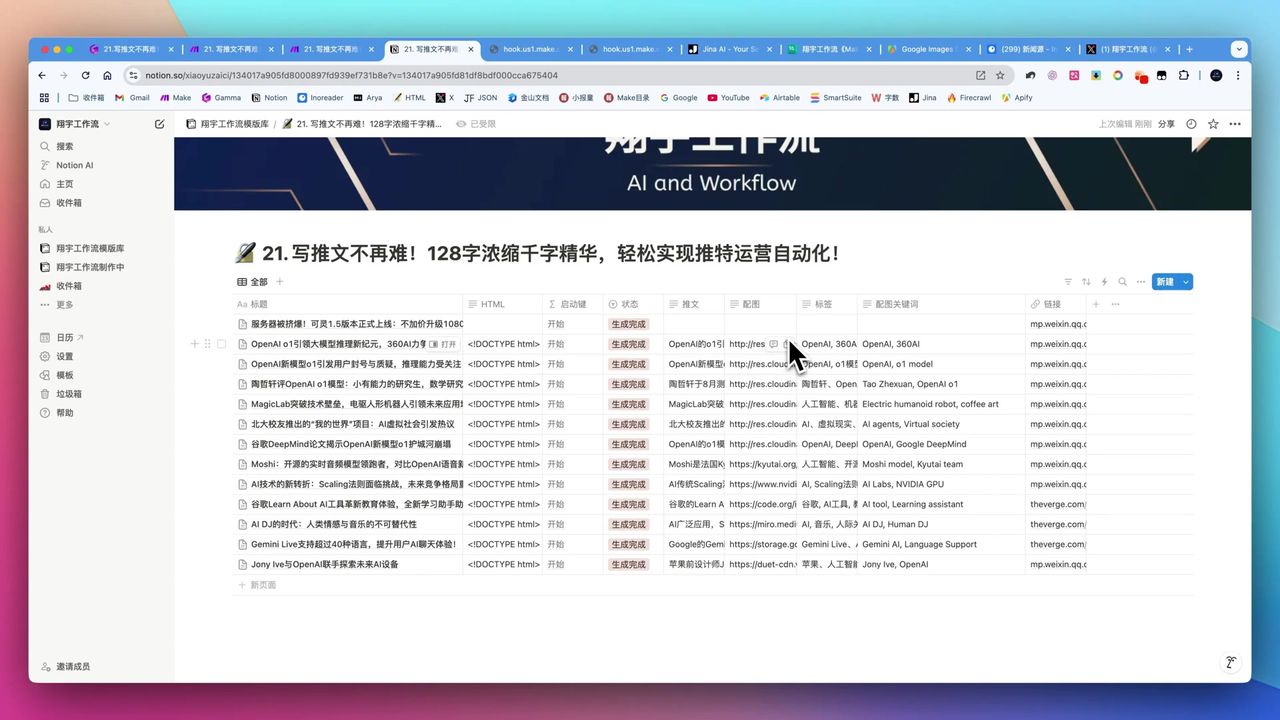
 完整工作流:Inoreader → Jina Reader → OpenAI → Notion
完整工作流:Inoreader → Jina Reader → OpenAI → Notion
核心决策因素
在选择或搭建此类自动化系统时,需要关注:
- 自动化稳定性 - 流程是否容易报错?抓取网页是否会被反爬?
- 内容质量 - AI生成的笔记是否具有”网感”,能否通过Prompt调整语气?
- API成本 - Inoreader专业版、OpenAI Token、Make.com操作数的综合成本
- 扩展性 - 能否轻易更换新闻源或分发平台?
技术配置参考
| 配置项 | 参数/设置值 | 备注 |
|---|---|---|
| 核心中枢 | Make.com | 负责串联所有服务 |
| 信息源 | Inoreader RSS | 配合API或文件夹订阅使用 |
| 抓取引擎 | Jina Reader API | 将网页转为LLM友好的Markdown |
| AI模型 | GPT-4o(建议) | 使用System/User双角色设定 |
| 输出格式 | JSON Mode | 强制返回结构化数据 |
| 字数限制 | <3000字符则丢弃 | 防止抓取失败导致质量差 |
| 目标字数 | 300-400字 | 小红书最佳阅读长度 |
| 数据存储 | Notion Database | 包含URL、正文、标签等字段 |
前置准备
在开始之前,请确保你已经准备好:
- Make.com 账号
- OpenAI API 密钥(建议GPT-4o)
- Notion 账号(用于存储生成的内容)
- Inoreader 账号(用于RSS订阅,需专业版以使用API)
- Jina Reader API(免费额度足够测试)
Step 1: 配置Inoreader信息源
在Inoreader中设置RSS订阅:
- 订阅目标领域的信息源(如AI、科技新闻)
- 创建文件夹或规则进行分类
- 获取API Token用于Make.com调用
在Make中添加Inoreader模块,获取最新文章列表。
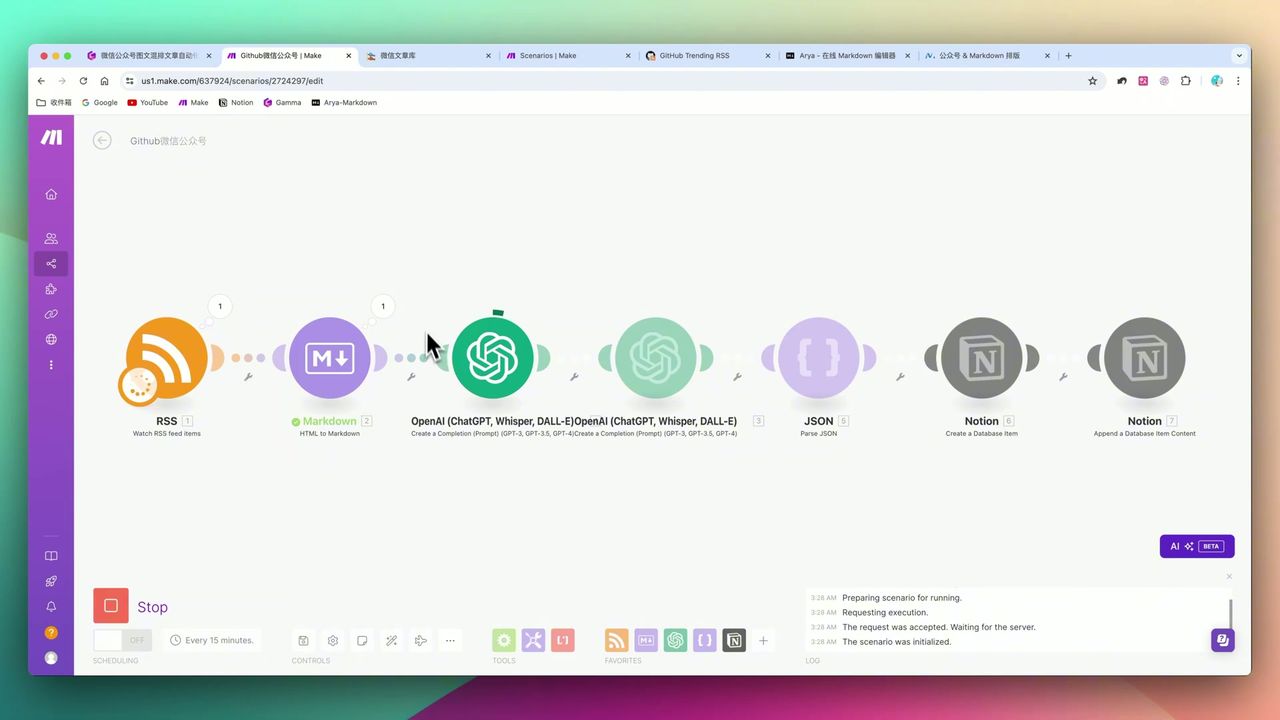
Step 2: 使用Jina Reader清洗内容
这是整个工作流的核心亮点之一。
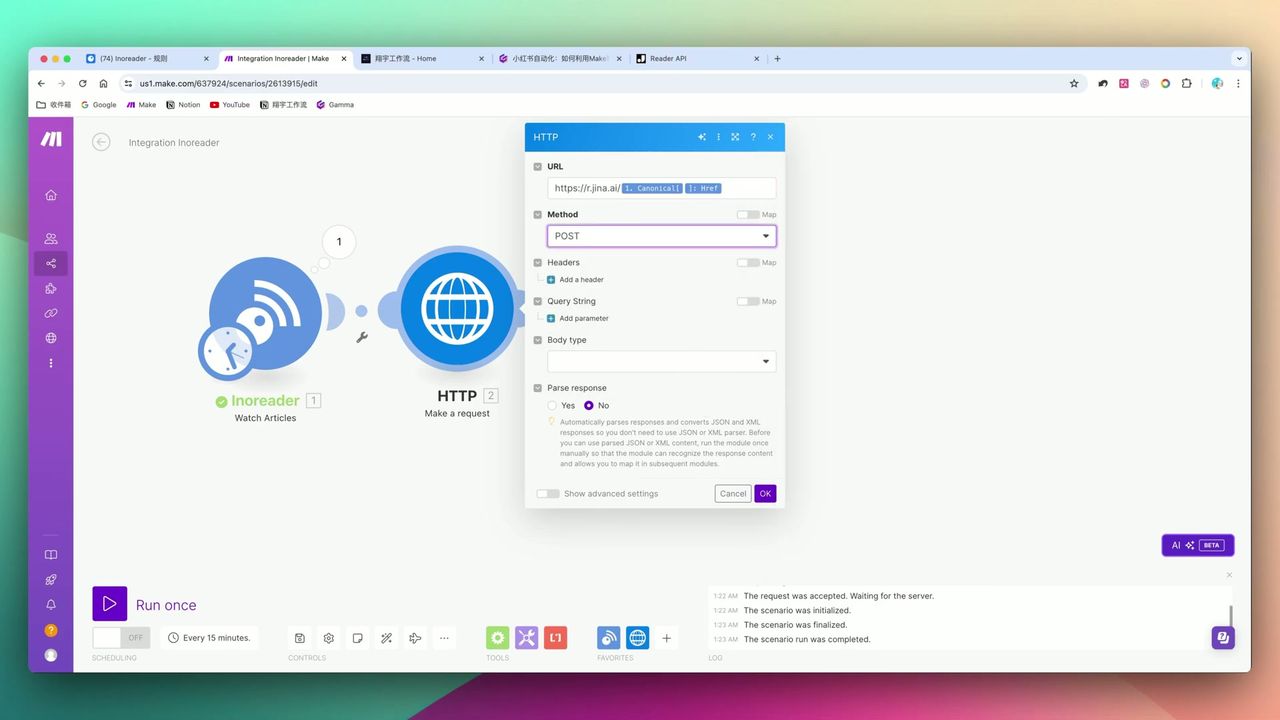 Jina Reader API的Header配置:Accept、Authorization等
Jina Reader API的Header配置:Accept、Authorization等
为什么需要Jina Reader?
直接抓取网页会包含大量HTML代码、广告、侧边栏等干扰信息:
- Token消耗会爆炸
- 干扰信息太多影响AI理解
- 可能包含敏感或无关内容
Jina Reader能将网页转换为干净的Markdown/Text格式,只保留核心文章内容。
配置要点:
- URL:
https://r.jina.ai/{{原文URL}} - Header:
Accept: text/markdown - 可选:
X-No-Cache: true
Step 3: 添加内容过滤器
为了保证质量,需要过滤掉抓取失败或内容过短的情况。
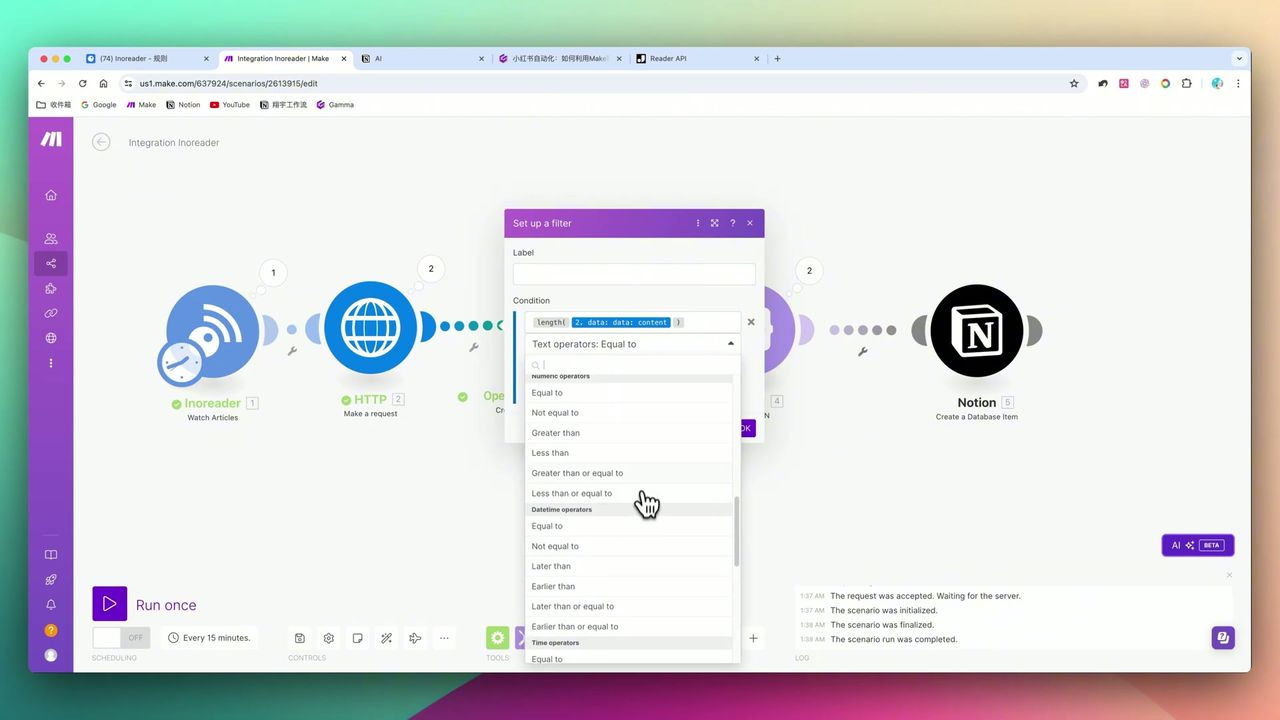 字符数大于3000的筛选逻辑
字符数大于3000的筛选逻辑
在Make.com的连线上添加Filter:
- 条件:原文长度 > 3000字符
- 作用:防止被反爬封锁或抓取失败导致生成质量差
注意:Jina Reader可能会遇到被封锁的情况,设置过滤器是必要的容错措施。
Step 4: 配置OpenAI生成笔记
使用详细的Prompt控制AI输出小红书风格的内容。
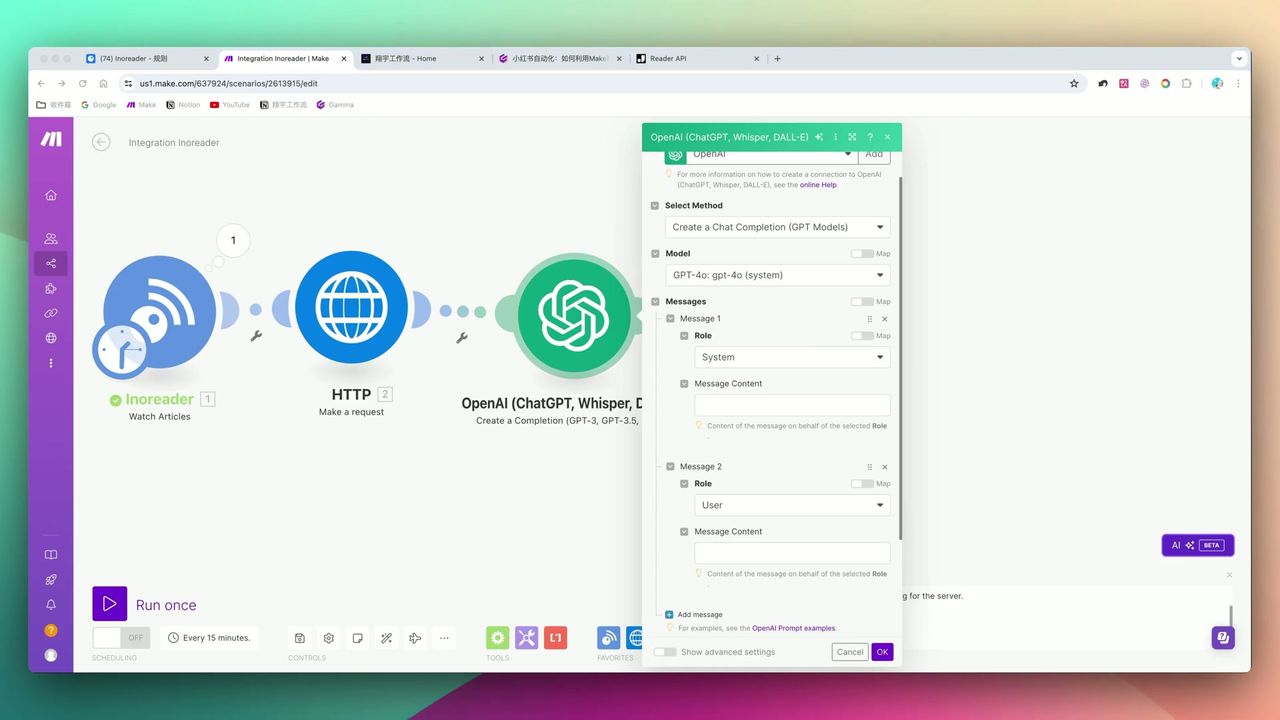 System Prompt和User Prompt配置界面
System Prompt和User Prompt配置界面
Prompt设计要点:
System角色:
你是一位专业的小红书博主,擅长将行业资讯转化为吸引人的笔记。
要求:
1. 标题要有吸引力,适当使用emoji
2. 正文300-400字,口语化表达
3. 包含3-5个相关标签
4. 输出严格JSON格式:{"title": "", "content": "", "tags": []}关键配置:
- Model: GPT-4o(质量更好)
- Response Format: JSON Mode(强制结构化输出)
- Temperature: 0.7(平衡创意和准确性)
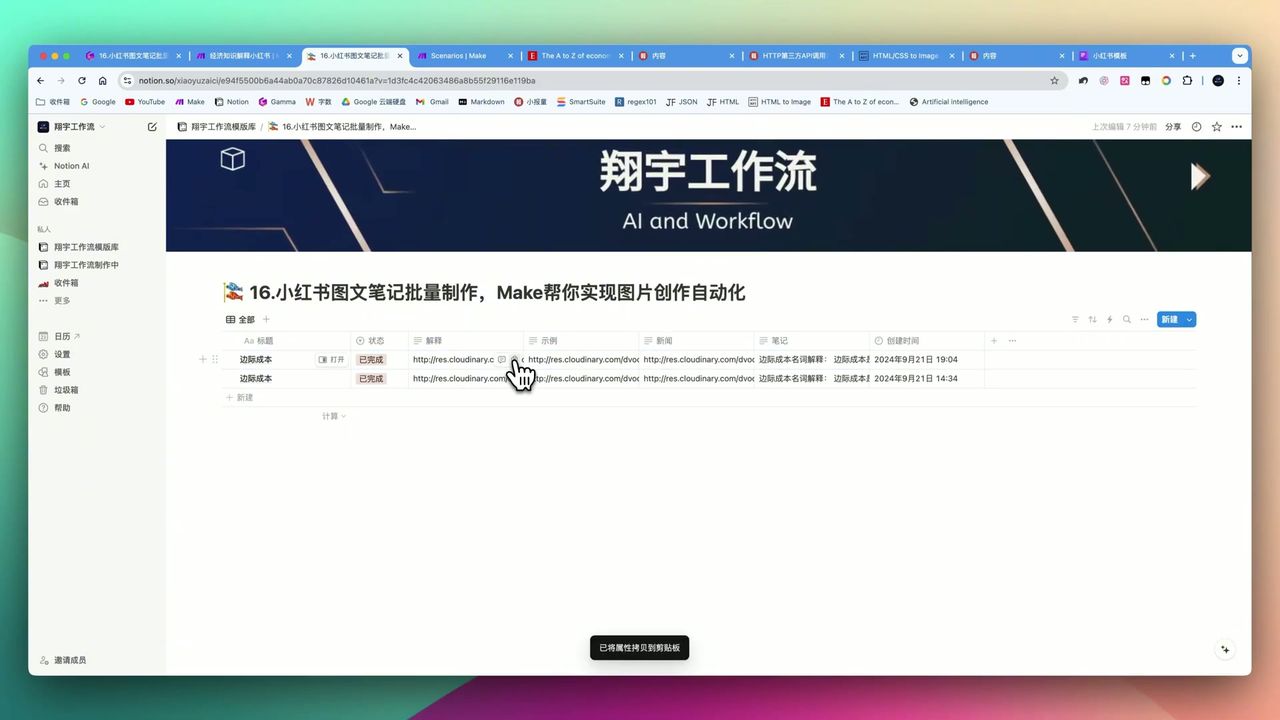
Step 5: 存储到Notion
将生成的结构化内容保存到Notion数据库。
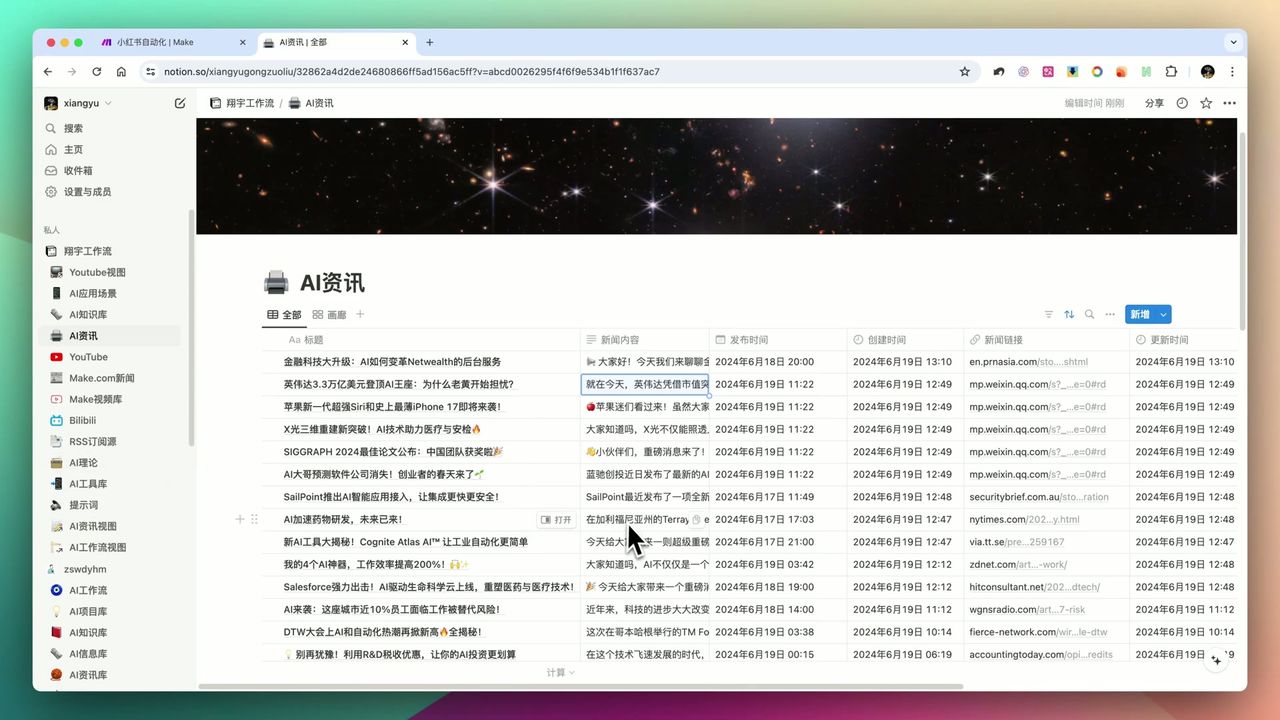 包含标题、正文、标签和URL的表格视图
包含标题、正文、标签和URL的表格视图
Notion数据库字段设计:
- 标题 (Title) - AI生成的爆款标题
- 正文 (Text) - 小红书笔记内容
- 标签 (Multi-select) - 相关话题标签
- 原文URL (URL) - 信息来源
- 状态 (Select) - 待发布/已发布
- 创建时间 (Date) - 自动记录
使用体验
工厂化的生产快感
一旦配置完成,体验极其爽快。从Inoreader抓取资讯,到Notion瞬间生成一篇包含标题、正文和标签的结构化笔记,整个过程无需人工干预。
强大的清洗能力
Jina Reader API能去除网页中多余的HTML代码,只提取核心文本。这一步至关重要,否则Token消耗会爆炸且干扰信息太多。
高度定制化
内容质量完全取决于Prompt设计水平。可以根据不同领域、不同风格调整提示词,上限很高。
注意事项
在搭建过程中需要特别注意:
-
抓取失败风险 - Jina Reader可能遇到被封锁的情况,必须设置过滤器容错
-
Make.com中文输入Bug - 输入中文时第一个字母可能不识别,需要手动修正
-
技术门槛 - 需要理解JSON解析、HTTP Header配置和Prompt Engineering
-
成本控制 - 高频运行时Token消耗不容忽视,建议监控用量
适用场景
推荐使用的用户
- 资讯类自媒体 - 需要搬运、翻译、改写行业动态的博主
- 产品经理/分析师 - 需要自动收集竞品动态并生成简报
- 科研人员/学生 - 需要追踪最新论文并生成摘要
- 运营团队 - 需要批量生产标准化内容
可能不适合的情况
- 纯原创/情感类博主(无法替代人格化创作)
- 对HTTP、JSON等概念完全陌生的用户
- 预算极低、不愿付SaaS订阅费的用户
常见问题
这套工作流的运行成本大概多少?
需要Inoreader专业版、OpenAI Token消耗和Make.com操作数费用。如果是海量新闻处理,Token消耗不容忽视,建议按实际使用量评估。
Jina Reader是什么?有什么作用?
Jina Reader是一个将网页转换为LLM友好格式(Markdown/Text)的API服务。它能去除网页中的广告、侧边栏等干扰信息,只提取核心文本,大幅降低Token消耗。
为什么要过滤掉小于3000字符的内容?
这是质量控制措施。过短的内容可能是抓取失败或被反爬封锁的结果,直接丢弃可以避免生成质量差的笔记。
可以直接发布到小红书吗?
目前工作流将内容存储到Notion,需要手动或通过其他工具发布到小红书。国内平台对自动发布普遍持谨慎态度。
下一步
学会了基础工作流后,你可以尝试:
- 添加更多RSS源,扩展信息来源
- 集成图片生成API,自动创建配图
- 添加定时触发,实现完全自动化
- 尝试对接其他平台(知乎、微博等)
有问题欢迎在评论区留言交流!
常见问题
- 这套工作流的运行成本大概多少?
- 需要Inoreader专业版、OpenAI Token消耗和Make.com操作数费用。如果是海量新闻处理,Token消耗不容忽视,建议按实际使用量评估。
- Jina Reader是什么?有什么作用?
- Jina Reader是一个将网页转换为LLM友好格式(Markdown/Text)的API服务。它能去除网页中的广告、侧边栏等干扰信息,只提取核心文本,大幅降低Token消耗。
- 为什么要过滤掉小于3000字符的内容?
- 这是质量控制措施。过短的内容可能是抓取失败或被反爬封锁的结果,直接丢弃可以避免生成质量差的笔记。
- 可以直接发布到小红书吗?
- 目前工作流将内容存储到Notion,需要手动或通过其他工具发布到小红书。国内平台对自动发布普遍持谨慎态度。